发布日期:2024-05-06 来源: 网络 阅读量()
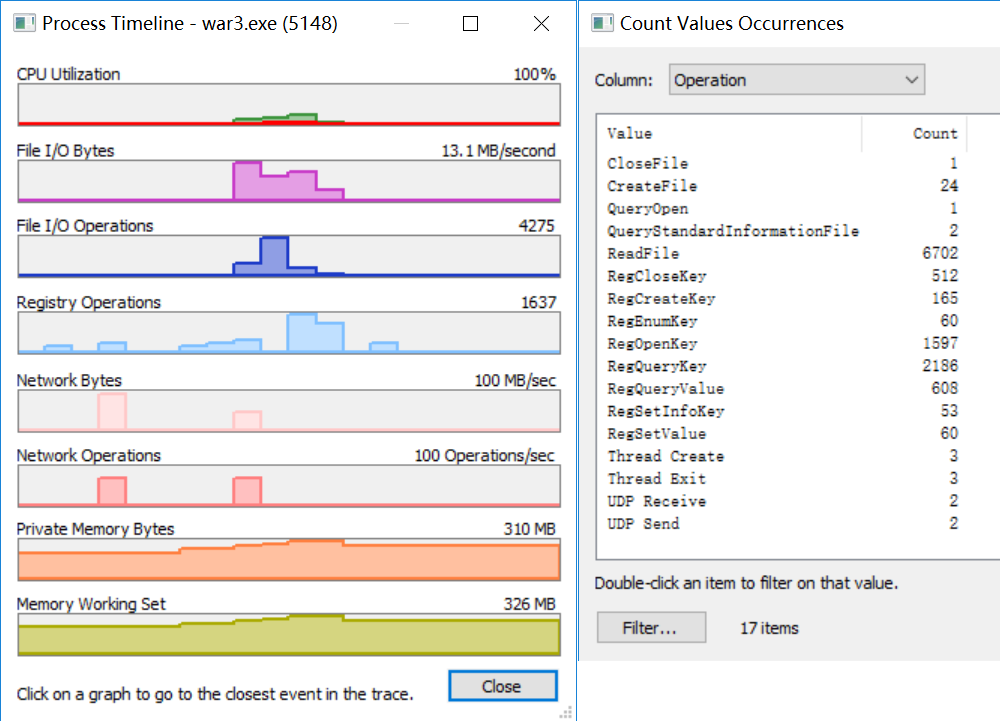
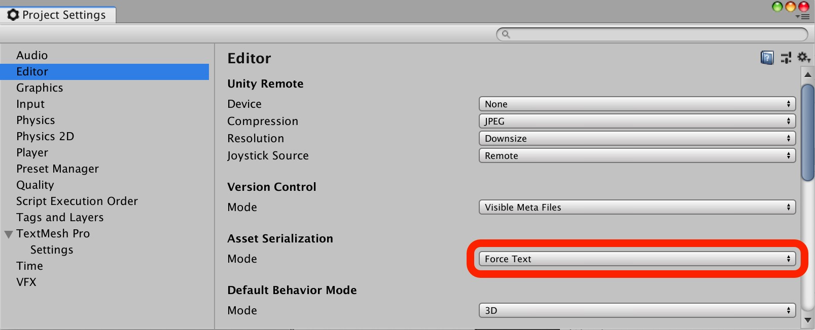
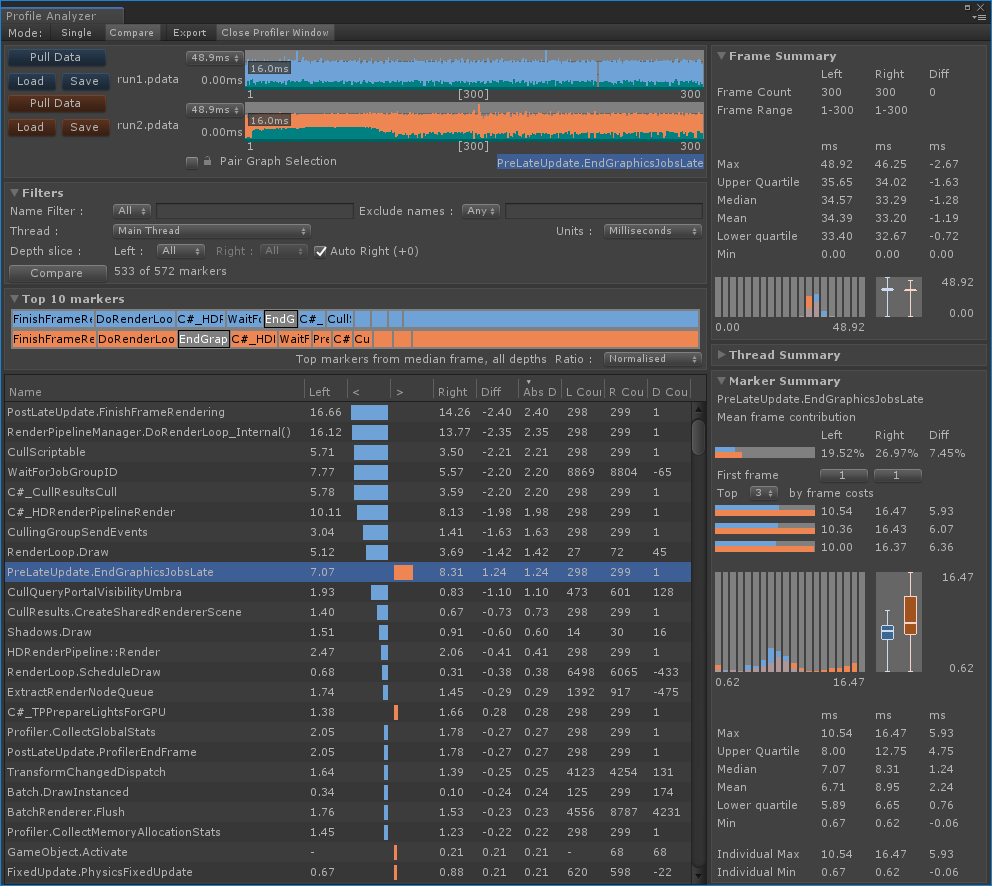
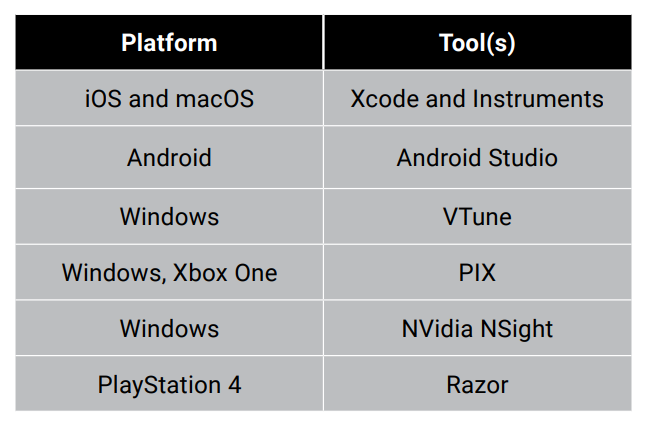
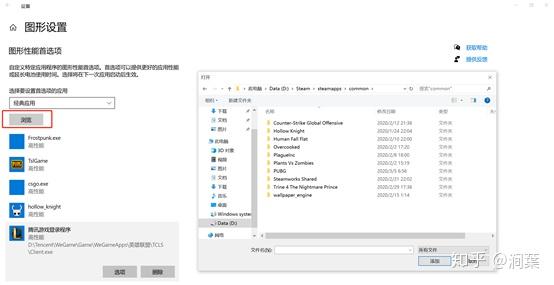
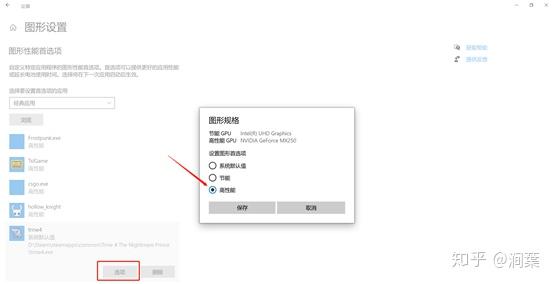
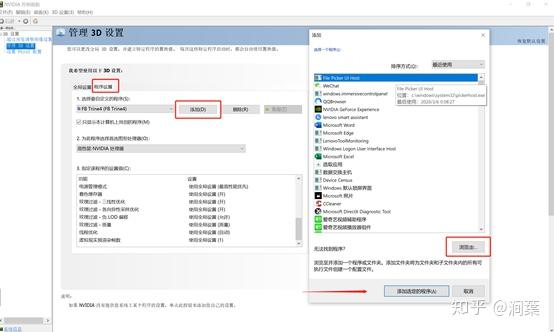
更新完成。 milo老师说了整个优化的大框架,那我来补充一点实践方面的知识好了,聊一下天涯明月刀OL的优化,下文把这个游戏简称天刀。这是一个大型mmorpg,pc平台,客户端程序员数量在25人以上,其中引擎程序员大约在10人不到。 天刀是我从业以来优化最久,投入最大的项目,没有之一。以前的AAA游戏,我们通常会有一个两个senior的程序员,进行数个月的优化,而天刀的优化,断断续续做了接近3年,长期来看平均有两个以上的senior程序员投入,整个引擎和游戏方方面面都做了好几轮优化。 优化的流程始于profiling,我们用过各种各样的工具,cpu性能方面包括比较大路一点的vtune,自制profiling工具,已经数个小众一点的基于sampler的cpu监测工具。为了监测各种卡顿,windows performance toolkit是最常用的利器,虽然相对难学点,但这是最好的查找卡顿的工具了,是windows平台上性能优化必须要掌握的工具。gpu性能方面gpa,perfhud用的比较多,中后期gpuview也很常用。至于为什么要用这么多不同的工具,主要是每个工具各有擅长,往往能看见其他工具不容易发现的盲区。 来几个有趣的优化例子,看看天刀这里的优化幅度: 1,milo老师的tag math+visibility组件,理念在2015年已经不算先进,但令人惊讶的是组件的效率。参考的dice公司同样的技术,运行在ps3的spu,这样的计算密集型特性,经过milo的优化,运行在普通cpu上,毫无压力,在i3的入门级cpu上,依然只消耗低于2ms的cpu时间。这个技术甚至颠覆了传统场景管理技术。天刀这个大场景远视距的游戏,玩过的朋友可能知道,场景复杂度和可视距离,都是国内少见的,即使和国外游戏相比,也只有逊色于just cause,farcry等不多的游戏,但是天刀里面的场景管理,没有用4叉树或者8叉树,直接扔进底层visibility组件。。。当然visibility组件里面还是有一些简单的类似管理,把这一层管理放到底层之后,场景管理和移动物体变得无比方便,对引擎层完全透明了。visibilty组件如此高效,以致阴影、树木、反射,全部可以由它来裁剪,简洁优雅。 在天刀早期做完大地形后,粗粗用visibility裁剪一下,帧数直接翻倍。后期主城场景密密麻麻,用到了其中的遮挡裁剪,看不见的就不画,又没有gpu的oclussion culling的延迟。 2,植被系统的优化。严格来说这不算优化,是一个特性。天刀植被用了speedtree,相当出色的中间件,基本一个美术就能把整个游戏需要的树全部建模出来了。于是我们就在考虑是不是可以在场景里面种满树,因为这个中间件也有类似的demo。但是结果并不令人满意,原生的技术在效率和质量上都不 够好。 开发同事在speedtree的基础上做了很多尝试和优化,效果被制作人几次拍死,最后终于达到了满意的质量,也就有了大家看见的漫山遍野得植被。远处树木本质上使用speedtree的billboard,但是在normal生成、树木根部和地形的融合等多方面做了很多尝试,对于树木建模,是多一些polygon,好降低fillrate(因为pre z可以裁剪掉后面的像素),还是用大一点的面,可以减少polygon,也做了细致的美术微调,找到了平衡。前后整个特性应该做了超过半年,初始效果做出来以后,在场景序列化、裁剪等方面又要做深度整合,而不能简单充用原先speedtree的整合方式。在远处使用billboard的树木,同事很创新的想出密度倍增的技巧,一下子就出现了震撼的全景植被效果。 天刀的植被目前来说,效果和效率应该是是顶尖的。我们在2014年给unreal引擎创始人tim sweeney展示的时候,他也表示这是他见过的最好的植被表现,能得到偶像君的肯定,团队也非常受鼓舞。更多细节我们今年下半年会有一个gdcc session,同事应该会介绍更多。 这个工作有一点值得注意,真正好的优化,是程序、美术等多团队共同努力的结果。在效果和效率上很多团队说起优化,就是程序定个指标,扔给美术去做,程序就不管了。这样做下去,很容易出现美术用力缩贴图减模型,效果一塌糊涂,帧数倒是没提高多少。真正好的优化,必须是多方一起坐下来,共同分析问题,一起解决,即使是纯美术的改动,也需要程序帮助定位问题,这样才更有针对性,才能把优化带来的质量损失降到最低。 3,卡顿优化,shader cache收集系统 天刀一测二测得到了较好的性能方面反馈,一方面的确优化的还可以,另一方面由于我们花了非常多的精力在防卡顿上面,导致游戏里面的卡顿相对较少,有玩家反映帧数只有20左右,但也能顺利玩下来。由此可见,片面追求高帧数意义不大,去掉性能上的spike,会给玩家更好的体验。 卡顿原因多种多样,单独就可以是一个很大的话题。我分几个单独案例来说。 一个情况是shader cache,天刀使用了uber shader的机制,根据场景和人物材质不同,可以组合出多种多样的shader,开发早期会在构建版本的时候穷举所有参数组合把shader全部编译出来,存在版本里面。很快这个方式就没法用了,shader参数组合爆炸了,于是就用动态生成机制,根据参数组合去取shader,如果之前没有编译过就同步编译,然后把编译后的shader保存到cache文件,以后要用就可以直接load。之所以这里没有在后台用别的线程编译,主要原因还是不希望编译的过程中模型不显示造成显示上的瑕疵。但是这样做的话,如果遇到缺失shader,就会有几百ms的卡顿了。 开发过程中这个同步编译当然无妨,但是见玩家的时候可不能这样,事实上三测一开始就因为bug,cache没处理好导致卡顿乱七八糟,被玩家喷死了。我们需要做的就是给玩家的版本里面需要把所有的shader组合都编译出来。 07年做xbox360游戏的时候也遇到过一样的问题,当时的团队有足够的测试资源,我们的方案是把所有用到过的shader参数存在文本文件,每天测试人员会把所有的参数发给我,我运行一个脚本去掉重复,整合所有的shader参数,然后第二天构建版本的时候就可以用收集的参数来预先生成所有的shader了。 但这次天刀项目组规模比较大,用类似的方法收集比较累。 我写了个简单的小server,测试版本都会上传所有的shader参数组合到这个小server,这个server会定期合并参数,输出后就可以上传到版本里面,下一个版本就可以构建这些shader了。 通过这个方法,我们在整个团队不受到干扰的情况下,收集了所有的shader参数组合。同时如果一个shader太久没有被用掉,也会被server去掉,这样如果因为更新程序导致shader改变,那些废旧的shader会在一段时间以后被慢慢淘汰,避免了shader的无止境增加。 4,卡顿优化,跨进程卡顿 有一阵子上线以后玩家表示卡得很,但只要删除cross组件(腾讯内部的一个通用组件),就会流畅很多。听到这个迷信的说法,大家都不以为然,自己测试一下,发现也没有重现。 可是过了一阵子,发现坊间这个传说越传越广,进一步测试,发现在主程或者群战的时候,的确有可能会有很多没发现的卡顿,这些都是我们开发版里面不能重现的。 开发同学用Windows performance toolkit查了很久,结论非常令人崩溃。 起源是Cross组件使用了内部的另一个登录组件,这个组件也被很多其他腾讯产品使用。每一帧cross更新的时候,这个登录组件都会去读一个系统的锁。如果在游戏内存占用量非常高的时候,这个系统锁的变量有可能被page out,于是引起了一个page fault,所以系统就会卡顿一下。我们内部的电脑都是SSD,所以page in也一般不是很慢,理论上也不应该卡啊。继续追查,发现出问题的机器上往往装了微云,微云经常读写硬盘,在多台电脑件同步数据。如果正好page in发生在读写数据的时候,就会卡了。换句话说,我们内部观察到的现象,是腾讯的微云读写一个文件,正好和游戏中那个系统级锁的page in过程重叠了,所以会卡。外部玩家如果用了其他腾讯服务,或者硬盘比较慢,也可能引起一样的问题。 解决方案就比较简单,把这块东西的update全扔到另一个线程就好了。 就先讲四个案例吧。可以看见在这几个案例里面,查找问题、解决思路都各不相同,但共同特点都是在程序端做了非常多细致的工作,也有一些非常有创意的解决方法。在我看来,优化绝不仅仅是设一个budget,对美术资源的大小、polygon数量等等设好限制,然后push他们去减贴图简化模型。程序作为性能的主导者,有非常大的主动性,如果能有很多更有创意的实现方式,可以大大简化美术的工作,也把性能和效果推到更极限。 叫野怪上班需要时间 原因1:加载的工作量不同。 用ProcMon稍微监控一下从点击按钮→读秒倒数→加载地图→进入战局的过程, SC(v1.18,Lost Temple)是这样的: 而WC3(v1.26,Lost Temple)是这样的: 后者光是ReadFile的操作数量就是前者的近4倍,截图中未显示的CPU使用时间(SC:0.42秒;WC3:2.38秒)更是近6倍。毕竟WC3版地图上到处都是树,一张图5000多个物件(SC版LT的物件基本全是矿,总数100出头)。这说的还只是普通的对战地图,像3C、DotA这种带自定义技能的RPG图又是另一个概念了。 原因2:电脑的配置代差。 从SC到ROC近4年半的时间,按摩尔定律主流配置性能已经翻三番(8倍)了。SC的系统需求是Pentium 90MHz+16MB内存;而ROC是Pentium 400MHz+128M内存。一个640*480*256色的游戏,说白了用ROC的底线配置去跑SC已经是高标准了,何况主频上G的P4。所以说你觉得WC3读图慢,SC秒进,那只是特定时期的特定体验,换成现在的碾压配置基本都是秒进。如果回到SC1刚出的那年,呵呵,那时候网吧还不叫网吧,叫电脑房,一排排的红警、Duke3D、真侍魂,那配置玩SC,一个启动画面就能读上两分钟,双击游戏图标就可以上厕所去了,回来还没进。 就是这张图,岁数小的朋友可能都不认识。因为SC1.0没火多久BW1.04就出了,读盘画面也被换成了绿皮K姐大特写(电脑房配置依然要卡1分钟以上),然后大家都欢快地去小狗变飞龙了。 单机游戏的话,基本上就是把人群当粒子(就像各种飞溅的火星、飘扬的雪花等会大量在同屏内出现但是行为足够简单的东西)来绘制,用LOD层关闭远方“人群”粒子的一些复杂功能。因为中远距离的人群占这种千人万人同屏的绝大部分,并且正常情况下玩家的大部分注意力是在近处的,中远距离的人群行为的简单僵硬很难被察觉。这种优化效果一般不错。 如果其他人都是player……迄今为止我是没见过真正做得到万人同屏的游戏,几千人同屏倒是有一个:EVE Online国服的49-U6U会战高峰期,同一战场(大约一亿立方公里的空间吧,数量级上应该差不多)上出现了大约3500名玩家。由于这个游戏的典型交战距离在数十到数百公里这个尺度,虽然玩家数量极多,但实际上绝大部分玩家驾驶的飞船都离彼此相当远,远到了只需要在那个位置画个图标而不需要把模型画出来的程度。 这么多玩家在同一区域联机,真正考验的实际上是服务器。EVE Online为了应对玩家间的大规模会战,采用了一种称之为时间膨胀的机制,实际上就是降低交战星系的时间流速——例如在最高的十倍时间膨胀下,一艘飞行速度300 m/s、每3秒开火一次的飞船,所有面板数据不变,但是以玩家经历的现实时间作为标准,它一秒只飞30 m,半分钟才会开一次火。 这样一来,以上述会战发生时的时间膨胀率,玩家们持续打了一天左右的会战实际上只是游戏中的两三个小时。理想状态下,这相当于服务器只需要处理常规速度下的350人左右的玩家作战。不过这个机制显然不能随便套用到其它游戏上,比如对各种响应时间要求非常高的FPS游戏就不行。 实话告诉你,就是不适合了,一堆在洗的不知道在洗什么。 拥有米8米9米10Pro,米8吃鸡就是卡,没得说,就算王者打大型团也会卡,这就是GPU算力不够了。 但主要原因不是845不行,而是腾讯不行,没有做好优化。芯片更新换代太快了,导致性能一直过剩,软件商为了更好的体验就会努力去吃性能,结果就是845带不动吃鸡。流畅+极限基本40-50帧了。 MIUI12的动态壁纸也很吃算力,于是我也取消了。只有新的处理器才能体会到新系统的快感。小米8配MIUI10,小米9配MIUI11,小米10配MIUI12才是最爽的。小米8刷了MIUI12之后明显卡顿。为什么呢,因为细节太多了,比如弹窗的毛玻璃效果,这需要GPU进行模糊处理,弹窗太快的话必然卡顿。 845很强,但是还不够强,845在今天只能算一个中端处理器水平,比如麒麟820这种。 fps游戏消耗确实很高,结论就是845真的不适合60帧吃鸡了。 顺便说一句,855也带不动HDR高清+60帧。 说清楚点,就是发热导致的,算力不够也是真的,降频降的。。。发热不是手机通病?哪个手机玩游戏不热的。。。。。。建议大家用用散热背夹吧。米8刷回MIUI10应该挺好 是的,没错,如果需要追求最高画质下的流畅稳定。那么845确实已经不适合了。不光是小米,任何845都已经不行了。 我简单介绍一下:中画质+崩坏三+845+深渊雷律开大=动画片(这个意思是,20帧以下)。 是的,如果只是逛街去村子看风景,那么高画质60桢没有压力,但实际上我们讨论流畅的时候,讨论的一定是团战+开大招的极限场景下也不能卡顿。 虽然845依然还是「高端处理器吊车尾」级别,但其实性能已经不够。考虑到今年的中端处理器事实上也只有845这个级别的性能,(参考https://www.socpk.com/)所以,其实,所有的中端机也同样不适合你对游戏的需求。 如果以高画质流畅游戏为要求,那么目前可用最低配置应该是855/990,如果新购机建议是 865/A13起步。 -- 原因嘛?别问,问就是安迪比尔定律。 手机处理器提升的性能,都会被游戏厂商吃掉。你的手机没变,但游戏本身升级了,它对硬件的需求会越来越高。 如果你希望能够持续流畅高画质的玩持续更新的网游,那么你必须坚持持续更换新款旗舰手机,不说每一代都换机,至少每隔一代旗舰处理器得换一次机。 用人工代替(减轻)计算机的工作。 现代计算机代码所做的工作,其实可以粗略分成两部分: 程序层面的优化,其实就是人工解决2,让计算机专心在1,从而整体工作量贴合在关键最短路径上。 比如,大家都知道一些高级语言,比如Python,运行效率是C/C++的1/10以下,甚至1/100。为什么呢?因为Python运行时除了要解决本来要解决的问题,还要补上所有程序员“偷的懒”。比如内存的分配与管理,比如类型安全与转换,等等。 再比如,大家都知道多线程能够提高CPU端的执行效率。但是多线程程序难写难调试,所以程序员开始在各个地方加锁,保证一些关键点的执行顺序。然而,加锁严重影响性能。多线程优化就是分析这些锁的必要性,去除不必要的锁或者用更为轻量级的方法去代替它。换句话说,就是人脑执行多线程的一部分,理清它们之间的关系,减少CPU端无谓的等待。 最后举个GPU端的例子。稍有了解的人应该知道3D渲染当中有Z测试,也就是深度测试。通过深度测试,可以保证以任意顺序绘制画面都能得到正确的结果。然而,这并不能保证最高的效率。比如,如果按照从远到近的顺序(或者不排序)进行绘制,那么一开始绘制的远处的物体很可能会被后面绘制的近处的物体遮挡,但是Z测试并不能预知这种遮挡的发生,远处的物体会被全部绘制出然后被近处物体覆盖,造成算力的浪费。 那么对于这种情况,如果改为从前往后绘制,就会节省很多GPU的算力开销:因为首先画近处的物体,那么后面画远处的物体时,被遮挡的那部分会直接在Z测试当中失败,从而不被绘制。 在上面的这些例子当中,各种做法都能得到正确且相同的结果。区别在于前者采用了更为通行广泛(Generic)的方法,可以适应各种情况但是相应地开销就大;而后者通过人力对于特定应用场景的分析,选择了更为有针对性的(Specific)的方法,得到了更好的性能。 所以,游戏的优化其实就好像用胶水把你搭好的乐高模型粘住一样,在失去Generic性的同时,使得模型整体更加强壮稳固。 所有的性能问题都可以归结于一句话:硬件受委屈了。 而这又分为两种情况: 1 它们承担了它们这个级别不应该有的压力。(超负荷运作) 2 它们没有受到应有的尊重。(低负荷运作) 而性能优化的过程实际上就是平衡硬件效率的过程,用合适的方案和方法把某一部分硬件的压力转换到另外一部分上去。又或者通过合适的方案,让硬件执行同一个任务的时候能耗更低。 比如,一台手机,GPU差,但是又偏偏分辨率高,在不动美术资源和逻辑的前提下,最大的收益就是降低渲染的分辨率,从而降低GPU的负担。 比如一台机器CPU差,但是内存大,那么在不动美术和逻辑的前提下,最大收益的方式就是减少IO和计算,将文件或者计算结果存入缓存,从而降低CPU开销。 再比如游戏中常用的合批技术,是因为GPU的速度大于CPU,所有少量多批次的提交会让GPU产等等待,造成CPU繁忙而GPU等待的情况,合批则可以降低GPU的空闲时间,从而完成性能优化。 比如光照贴图,烘焙阴影则是提前将光照信息烘焙到纹理贴图,运行时候直接从纹理中获取数据而不用实时计算,从而降低GPU的计算耗时,以内存换取GPU的执行效率。 比如不同平台的纹理格式压缩,是为了适配GPU的特性,把资源处理成GPU最高效率的执行格式,从而降低CPU或者GPU的解码损耗。 然后,对于移动平台,尤其是安卓平台,之所以优化难做是因为机型太多,硬件组合完全无法预知,也就无法提前做出硬件平衡。只能做一些行业内通用的优化手段,或者挑选一款机型最为最低机型,以改机器为基础进行方案变更。 而主机和IOS的专项优化实际上更加简单一些,尤其是主机,因为他们的硬件相对固定,可以进行最大限度的硬件压榨。 更详细的概念,可以看看我之前的回答: 在手机上跑3A开放世界…… 题主不妨问问所谓的大神们敢不敢接这氪命活儿。 所以说,MHY应该早日加入DLSS的支持,这玩意真是个改变游戏“优化”风评的利器。 B站上喷MHY游戏优化差的人比比皆是,知乎反而没那么多。经常会看到有人说某PC大作的优化薄纱MHY。但他们说的这些大作在同分辨率,全画质选项拉最高的情况下,对硬件的压力都是超原神崩铁的,帧率理所当然也低一些。为啥明明这样它们还是坚持MHY的优化最差呢? 排除云玩家跟风硬黑的情况,我在跟部分B友交流后发现,它们所谓的“全最高画质”,无一例外都是指原神或者崩铁的渲染精度拉满,同时吧它们提到的大作中的DLSS选项“拉满”。我甚至见过咬定DLSS选项中”最高性能“才是最高画质的人。结果上变成了实际上用原神8K分辨率对比各种大作的1080P甚至更低的分辨率。这原神崩铁的”优化“能好就有鬼了。 而且MHY确实存在问题,就是这个”渲染精度“的提升实在太小。4K下拉这个我根本看不出有什么区别,如果用抗锯齿跟2.0渲染精度比的话,2.0精度的效果远不如抗锯齿SMAA。我都不知道MHY搞这么高渲染精度的目的在哪。 而很多PC大作就很聪明,这个渲染精度的最大值是100%。就是说,你只能降低你的渲染精度来降低负载,并不允许你调高。 还有一点就是,很多人评价画质好坏的观点是”是否真实“。这个就没啥好说的了,MHY肯定是被薄纱的。 不过并不是MHY的优化没有问题。原神崩铁部分场景会出现较为频繁顿卡(或者说掉帧),这个和画质选项和硬件性能没有关系,众生平等。这肯定是优化的问题了。 大厂3A优化那么好,一定能在一台不到10mm厚、6~7寸屏、被动散热、5G信号、高度集成的设备上流畅运行开放世界吧。 以往我们优化cpu的时候,为了降低Drawcall的消耗,我们通常采用静态批处理,动态批处理等技术,然而这也是有弊端的。通常一个大的场景中,存在大量相同的植被等物件,静态批处理后,对内存的增加是非常大的,动则就是几十兆的内存。而动态批处理,对于合批要求挺多的,同时可能存在,动态合批消耗过大,得不偿失。如果我们自己在逻辑代码里面进行动态合批,对于mesh的readwrite属性是要求开启的,这无疑也增大了内存的占用,复杂的合批处理可能会消耗更多的cpu时间。 Unity在5.4版本及之后,新增了一项功能,那就是GPU Instancing。GPU Instancing的出现,给我们提供了新的思路,对于大场景而言将所有的场景物件一次性都加载,对内存来说是很有压力的,我们可以将这些静态的物件如植被等全部从场景中剔除,而保存其位置、缩放、uv偏移、lightmapindex等相关信息,在需要渲染的时候,根据其保存的信息,通过Instance来渲染,这能够减少那些因为内存原因而不能合批的大批量相同物件的渲染时间。下面这两张图都是同个场景下渲染多个gameobject,图1开启了GPU Instancing,而图2没有。 图 1 图 2 在Unite2017大会上Unity的开发工程师为我们演示了关于GPU Instancing的一些实现,但目前它只支持标准的表面instance,同时不支持lightmap、灯光探测器、阴影、裁剪等功能。这些都需要我们自己来实现。(这里只指Unity5.6及前面的版本) 首先我们来看看Unity自带的支持标准表面着色器,通过 可以创建一个标准表面着色器(instance),下面是此着色器中的一段代码 (PS: 我所实验的是Unity 5.5的版本,而Unity5.6中已经没有这个选项,同时Unity5.6在材质属性面板中有一个Enable Instance Variants 勾选项,勾选表示支持Instance) 然后再来来看看官网文档Vertex/Fragment着色器的例子,shader代码如下 最后针对上面的Shader来解释下其中的几条关键宏。 UNITY_VERTEX_INPUT_INSTANCE_ID 用于在Vertex Shader输入 / 输出结构中定义一个语义为SV_InstanceID的元素。 UNITY_INSTANCING_CBUFFER_START(name) / UNITY_INSTANCING_CBUFFER_END UNITY_DEFINE_INSTANCED_PROP(float4, _Color) UNITY_SETUP_INSTANCE_ID(v) UNITY_TRANSFER_INSTANCE_ID(v, o) UNITY_ACCESS_INSTANCED_PROP(_Color) 当然首先我们还是得在我们的通道中包含指令,不然都是白搭。 - lightmap的支持 - 对Unity内置lightmap的获取。我们定义两个编译开关,然后在自定义顶点输入输出结构包含lightmap的uv。 然后在顶点函数中进行如下处理 最后在像素函数中进行解码处理。 DecodeLightmap函数可以针对不同的平台对光照贴图进行解码。 当然我们也可以通过属性来将lightmap传递给shader,这里就不写了。 - 阴影 - 当使用标准表面着色器时,Unity可以轻易的为我们提供阴影支持,但Vertex/fragment着色器中我们需要增加一些指令,同时还需要自己添加阴影投射通道。首先增加标签,表示接收正向基础光照为主光源。 然后增加如下指令,确保shder为所需要的通道执行正确的编译,同时因为我们需要里面的光照处理。 同时在我们的输入输出结构中添加 LIGHTING_COORDS宏,这个宏指令定义了对阴影贴图和光照贴图采样所需的参数。 完整的代码如下: 有了上面的通道还不够,那只是告诉着色器,我们能够捕获到其阴影所需的一切了;最后我们需要阴影投射通道 - 裁剪 - 裁剪,我们可以通过逻辑控制来进行处理,一是场景加载策略,如四叉树场景管理,根据当前所在区块来决定渲染目标,二是通过当前摄像机空间来裁剪目标,这里简单的说下通过摄像机视锥体空间裁剪的方法(四叉树动态场景管理网上搜索是有demo的) 在C#端,我们可以通过Graphics.DrawMeshInstanced 接口直接向GPU输送绘制调用,这里在初始化阶段随机的生成了一些位置信息,然后在每帧更新阶段调用 Graphics.DrawMeshInstanced 接口进行绘制 下面场景中使用了1023棵树,8*1023棵草。用1023这个数是因为DrawMeshInstanced传递的矩阵长度为1023,而1023个mesh其实是分成3个drawcall完成的。 UnityInstance.cginc中是这么定义的: #define UNITY_MAX_INSTANCE_COUNT 500 所以一个drawcall只能允许最大500个实例。另外,这里草和树的shader是我用了js的资源,所以阴影和lightmap的我就没增加,我用cube这个模型做的demo里是有这方面处理的。 在OpenGL ES3.0及以上设备中,我们完全可以使用GpuInsttance技术来更好的提升我们的游戏性能,将更多的Cpu时间留给复杂的逻辑,比如说战斗等游戏体验要求较高的模块;而在较旧的ES2.0的设备,我们完全可以采用现有的做法来兼容,而这时候我们可能需要做的更多的就是精简模型,通过Lod等其他策略来进行优化。 本篇难度:★★★☆☆ 性能优化是游戏项目开发中一个重要且必须的元素。用户和项目的需求在并且会持续增长。而即便在硬件设备高速发展的今天,游戏特效、画质、场景复杂度的需求也都向着榨干硬件性能的趋势提升,无论研发团队有多么丰富的经验积累,性能优化永远是一个非常棘手而又无法绕开的问题。 实际上,通过百度、谷歌、知乎可以搜到大把关于Unity性能优化的文章,但大多只是简单的论述、介绍、翻译和转载,或针对某中特定问题优化方式的教程。因此,我们在这里推出Unity3D性能优化系列文章,旨在给读者提供一个全面、易懂、可操作的unity优化教程,以便初学者学习使用。 在这里,我们的第一篇文章,主要作为一个引导,通过讲解对unity优化工具的了解及使用,给读者提供在实际项目中,进行游戏性能优化的流程和思路。 提起游戏性能,首先要提到的就是,不仅开发人员,所有游戏玩家都应该会接触到的一个名词:帧率(Frame rate)。 帧率是衡量游戏性能的基本指标。在游戏中,“一帧”便是是绘制到屏幕上的一个静止画面。绘制一帧到屏幕上也叫做渲染一帧。每秒的帧数(fps)或者说帧率表示GPU处理时每秒钟能够更新的次数。高的帧率可以得到更流畅、更逼真的动画。 现阶段大多数游戏的理想帧率是60FPS,其带来的交互感和真实感会更加强烈。通常来说,帧率在30FPS以上都是可以接受的,特别是对于不需要快速反应互动的游戏,例如休闲、解密、冒险类游戏等。有些项目有特殊的需求,比如VR游戏,至少需要90FPS。当帧率降低到30FPS以下时,玩家通常会有不好的体验。 但在游戏中重要的不仅仅帧率的速度,帧率同时也必须非常稳定。玩家通常对帧率的变化比较敏感,不稳定的帧率通常会比低一些但是很稳定的帧率表现更差。 虽然帧率是一个我们谈论游戏性能的基本标准,但是当我们提升游戏性能时,更因该想到的是渲染一帧需要多少毫秒。帧率的相对改变在不同范围会有不同的变化。比如,从60到50FPS呈现出的是额外3.3毫秒的运行时间,但是从30到20FPS呈现出的是额外的16.6毫秒的运行时间。在这里,同样降低了10FPS,但是渲染一帧上时间的差别是很显著的。 我们还需要了解渲染一帧需要多少毫秒才能满足当前帧率。通过公式 1000/(想要达到的帧率)。通过这个公式可以得到,30FPS必须在33.3毫秒之内渲染完一帧,60FPS必须在16.6毫秒内渲染完一帧。 渲染一帧,Unity需要执行很多任务。比如,Unity需要更新游戏的状态。有一些任务在每一帧都需要执行,包括执行脚本,运行光照计算等。除此之外,有许多操作是在一帧执行多次的,例如物理运算。当所有这些任务都执行的足够快时,我们的游戏才会有稳定且理想的帧率。当这些任务执行不满足需求时,渲染一帧将花费更多的时间,并且帧率会因此下降。 知道哪些任务花费了过多的时间,是游戏性能问题的关键。一旦我们知道了哪些任务降低了帧率,便可以尝试优化游戏的这一部分。这就是为什么性能分析工具是游戏优化的重点之一。 如果游戏存在性能问题,游戏运行就会出现缓慢、卡顿、掉帧甚至直接闪退等现象。在我们尝试解决问题前,需要先知道其问题的起因,而尝试不同的解决方案。若仅靠猜测或者依据自身原有的经验去解决问题,那我们可能会做无用功,甚至引申出更复杂的问题。 在这些时候我们就需要用到性能分析工具,性能分析工具主要测试游戏运行时各个方面性能,如CPU、GPU、内存等。通过性能分析工具,我们能够透过游戏运行的外在表现,获取内在信息,而这些信息便是我们锁定引起性能问题的关键所在。 在我们进行Unity性能优化的过程中,最主要用的到性能分析工具包括,Unity自带的Unity Profile,IOS端的XCode ,以及一些第三方插件,如腾讯推出的UPA性能分析工具。 我们主要针对Unity Profile进行讲解,之后也会略微介绍另外一些性能分析工具。 Unity Profile是Unity中最常用的官方性能分析工具,在使用Unity开发游戏的过程中,借助Profiler来分析CPU、GPU及内存使用状况是至关重要的。 首先我们来了解Unity Profile的面板: 在下图中我们可以看到Unity Profile面板,其中有很多profilers,每个profiler显示我们当前项目一个方面的信息,如CPU、GPU、渲染(Rendering)、内存(Memory)、声音(Audio)、视屏(Video)、物理(Physics)、ui及全局光照(global illumination)。 当项目运行时,每个profilers会随着运行时间来显示数据,有些性能问题是持续性的,有些仅在某一帧中出现,还有些性能问题可能会随时间推移而逐渐显出出来。 在面板的下半部分显示了我们选中的profilers当前帧的详细内容,我们可以通过选择列标题,通过这一列的信息值来排序。 当我们在层级视图中点击函数名字时,CPU usage profiler将在Profiler窗口上部的图形视图中高亮显示这个函数的信息。比如我们选中Cameta.Render,Rendering的信息就会被高亮显示出来。 我们可以Profiler的左下的下拉菜单中选择Timeline。 Timeline显示了两件事:cpu任务的执行顺序和哪个线程负责什么任务。线程允许不同的任务同时执行。当一个线程执行一个任务时,另外的线程可以执行另一个完全不同的任务。和Unity的渲染过程相关的线程有三种:主线程,渲染线程和worker threads。了解哪个线程负责哪些任务的用处非常之大,一旦我们知道了在哪个线程上的任务执行的速率最低,那么我们就应该集中优化在那个线程上的操作。 以上所显示的数据依赖于我们当前选择的profiler。例如,当选中内存时,这个区域显示例如游戏资源使用的内存和总内存占用等。如果选中渲染profiler,这里会显示被渲染的对象数量或者渲染操作执行次数等数据。 这些profiler会提供很多详细信息,但是我们并不总需要使用所有的profiler。实际上,我们在分析游戏性能时通常只是观察一个或者两个profiler,而不需要观察的我们可以通过右上角的”X”关闭,如果需要在添加回来,可以通过左上角Add Profiler。 当然,除了CPU usage profiler,Unity Profiler中其他的Profiler在一些场合也非常的有用,比如GPU、内存、渲染等,其使用方法和CPU usage profiler也是大同小异,可以按照以上的步骤来查看并学习。 我们在观察数据时,需要观察的目标有如下几点: CPU: 2. Time ms: 注意占用5ms以上的选项 内存 在了解了Unity Profiler后,现在我们在一个实际项目中来进行一次性能分析。同时来了解一般在实际项目中,主要会引起也是我们主要去观察的性能问题出现在什么地方。 以下是我做的一个简单的游戏项目,并未做任何性能优化并且有大量引起性能问题的代码,可以更方便大家观察其性能问题,在之后我会把工程上传到github供初学者下载分析。 我们来看一下在CPU usage profiler面板中的可观察项,在项目中我们可以先关闭VSync垂直同步来提高帧率。 下图中我关闭了除VSync之外的显示,可以看到VSync的消耗 具体步骤是edit->project settings->Quality,在Inspector面板中,V Sync count选择don’t Sync. 在关闭垂直同步后,我们继续看我们的项目 可以看到,我们以Total和Time ms排序,在图中拉黑的项(Camera Render)始终排在最前面。 如果说,在我们性能分析中,渲染已经没有什么问题,那么我们接下来要重点观察的就是GC,也就是垃圾回收性能分析。 如果我们也排除了GC的问题, 那么再接下来,我们就要考虑到是否是脚本的一些问题造成性能损耗。 这里的脚本,可能是我们自己写的代码,也有可能是我们使用的一些插件的代码。在CPU usage profiler面板中,我们可以关注Script这一项。 首先我们按照Time ms来排序,然后选择信息列表中的项目,如果是用户脚本的函数,那么在Profiler上方会有高亮脚本的部分。这种情况,说明游戏的性能问题是和用户脚本相关的,如下图中的显示,这部分脚本性能问题一定是与我们FixedUpdate有关。 同时,我们还可以再关注一些物理、ui方面的性能问题。 在上面我们讨论的,是几种最常见的性能问题,在实际项目优化中,如果有性能问题也逃不开这些,如果在这些方向都已经达到了我们的要求,但我们的游戏仍然有性能问题,我们应该遵循上面的方法解决问题:收集数据——>使用CPU usage profiler查看信息——>找到引起问题的函数。一旦我们知道了引起问题函数的名字,我们便可以针对性的,对其进行优化处理。 在开头我们说过,在我们进行Unity性能优化的过程中,最主要用的到性能分析工具包括,Unity自带的Unity Profile,IOS端XCode Capture GPU frame以及一些第三方插件,如腾讯推出的UPA性能分析工具。 这里我们简单的介绍一下XCode和UPA. Xcode是 Mac OS X上的集成开发工具。在我们打包Unity IOS的项目时,必须使用到Xcode来帮助我们打包及发布。 Xcode的功能也十分的强大,在我们开发IOS端时,可以使用其GPU frame Capture 功能为我们的项目进行性能优化分析。 在unity中,我们打包时在Run In Xcode as 选择debug模式,并且勾选Development Build 以下是GPU frame Capture具体功能的界面,在图形化界面中,可以在游戏运行时清晰的了解到CPU、GPU、内存的使用情况。 UPA是腾讯和Unity联合打造的一款性能分析工具,据说王者荣耀的性能优化分析就有使用到UPA,具体的使用方法可以通过客户端性能测试【腾讯WeTest】去了解。 好了,本期文章就到这里,旨在抛砖引玉,下一篇我们就会进行在Unity中CPU、GPU及内存优化方面的探索及优化方法的详细介绍。 本篇难度:★★★☆☆ 大渣好,我又来了。 之前的文章中,我们了解了Profiler工具,以及在实际项目中unity的CPU优化分析及方法,本文我们主要了解在我们的项目中GPU的性能分析,以及对GPU性能进行优化的相关技术。 在了解优化渲染前,我们需要了解在unity中,每一帧的渲染CPU和GPU都做了些什么: 1)CPU检查场景中每个对象,决定他们是否应该被渲染。(这些对象只有满足一定的条件才会被渲染。) 2)CPU收集即将被渲染的对象信息,并把这些信息分类为渲染指令(也就是draw calls,我们在之前的文章中也有提到,Draw Call实际上就是一个命令)。一个draw call包含网格数据以及网格如何被渲染。在某些场景,共享设置的一些对象可能会被合并为一个draw call。合并不同对象的数据到同一个draw call被称作batching。 3)CPU给每个draw call创建一个数据包,称为batch。每一个batch必须包含一个draw call。 4)CPU会发出指令,使GPU改变一些渲染状态。这个指令被称为SetPass call。SetPass call通知GPU,如何去渲染下一个网格。只有在渲染下一个网格时,其渲染状态相对于渲染上一个网格发生了变化时,才会调用SetPass call。 5)CPU把draw call发送给GPU。draw call通知GPU使用最近的SetPass call去渲染指定的网格。 6)有时,batch可能需要不止一个的pass。pass是shader代码的一部分,而新的pass需要改变渲染状态。对于batch中的每个pass,CPU必须发送一个新的SetPass call然后必须要再次发送draw call。 7)GPU按照CPU发送的指令顺序处理这些指令。 8)如果当前任务是SetPass call,那么GPU更新渲染状态。 9)如果当前任务是draw call,那么GPU渲染网格。渲染网格发生在很多阶段,不同阶段的shader代码可以定义渲染。其中:顶点着色器vertex shader告诉GPU怎么处理网格的顶点。片元着色器fragment shader告诉GPU怎么绘制单独的像素。 10)以上过程会重复执行,直到所有CPU发送的任务都被GPU完成。 我们下面列举以上几个方面具体的优化方法及技术 1.手动减少场景中物体的数量 这是一个最直观且有效的方法,比如在多人游戏中,我们可以减少可见玩家的数量,如果不影响游戏性和玩家体验,那这是就是一个即方便又快捷的方法。 2.Occlusion Culling(遮挡剔除) 遮挡剔除的原理就是当一个物体被其他物体遮挡住,不在摄像机的可视范围内时不对其进行渲染。具体方法如下所示: 可以看到,在场景中被遮挡部分并没有被渲染。 3.摄像机Clipping Planes 我们可以通过摄像机的Clipping Planes 的Far裁剪远端,从而降低摄像机的绘制范围,如同所示: 在游戏中,实时的光照、阴影、反射可以极大的提升观感,但这些操作需要耗费极高的性能。 Unity灯光默认是实时光照,也就是说物体在灯光下不同位置会产生不同灯光效果,由于动态光源在实时光照下会友大量的Setpass Calls,为了减小Setpass Calls,我们可以烘焙灯光效果,Unity会为我们生成光照贴图,这样大大减少了Setpass Calls。 2.阴影 在unity中,阴影相关的优化我们可以在质量设置中进行 3.反射探头 反射探头没有很好的优化方法,在我们实际的项目中却常会用到,以创建更真实的反射,但却会增加batches, 所以我们应该在性能消耗较大的场合尽量最小化其使用率。 2.纹理图集 纹理图集是把大量的小纹理合并为一张大的纹理图的技术,当我们使用这个技术为游戏创建美术资源时,我们可以确保物体共享同一图集,因此适合合并。Unity内置了图集工具老版本为Sprite Packer,新版本为SpriteAtlas。具体使用方法如下图。 1.顶点处理。顶点处理是指GPU需要渲染网格中每一个顶点的工作。 2.填充率。填充率是指GPU在屏幕上每秒可以渲染的像素数。如果我们的游戏受到填充率的限制,意味着我们的游戏每帧尝试绘制的像素数量超过了GPU的处理能力。 3.显存带宽。显存带宽是指GPU读写其专用内存的速度。如果我们的游戏速度受限于显存带宽,通常可能是我们使用的纹理太大,以至于GPU无法快速处理。 对于GPU优化问题我们主要可以通过下面几个技术来进行 1.纹理压缩 纹理压缩技术可以同时极大的降低纹理在磁盘和内存中的大小。如果是显存带宽的问题,那么使用纹理压缩减小纹理在内存的大小可以帮助改善性能,Unity提供了很多纹理压缩的格式和设置,运用也十分简单,根据不同的需求、机器和场景我们使用的方式也有所不同,具体可以参照Unity 官方文档 2.Mipmap 如果我们的场景包含距离摄像机很远的物体,我们可以通过使用miapmap来缓解显存带宽的问题,mipmap的主要作用便是模型的贴图会根据摄像机距离模型的远近而调整不同质量的贴图显示,以达到优化目的。其用法如下图所示 下图中两个物体其一没有设置mipmap,我们来查看发生了什么变化 3.LOD LOD与Mipmap类似,根据距离的远近使用不同精度模型,远处选择低精度的模型,近的时候选择高精度模型,这样就可以减少模型上面的顶点和面片数量从而提高性能。 可以看到随着摄像机位置的移动,我们的粒子会发生大、中、小三种变化(如果我们使用三种精度的模型,同样,随着摄像机的位置改变,模型的精度也就会发生变化。那么可想而知,性能损耗也就会发生改变) OK,本文到这里就宣告一个段落,在之后的文章中我们也会相应的带入其他性能优化方法。这里作一个预告,下一篇文章中,我们会主要讲解shader相关的内容。 如果有想进一步系统地学习游戏开发的,欢迎强势插入http://levelpp.com/。 帮助你发行游戏的Unity专家贴士 原文链接: 几乎所有游戏都是携着一个创新的灵感和一个工作室制作最好的游戏的希望降生于世的。这是一个伟大的事业,而且它可能带来很大的回报。但是在发行一款完整的以及优化好的游戏的旅途上有着无数挑战。 考虑到这一点,来自Unity的Integrated Success Services(ISS)的专家们准备了这个指南——围绕9个重要的研发领域——以帮助你更好地理解并避免常见地内存、性能和平台问题。 研究特性需求和目标平台 在启动你的项目之前,先透彻地研究你的特性需求和目标平台。确保所有的目标平台都支持你的需求(例如,在低端移动设备不支持实例化渲染)。一定要考量清楚你准备做的可能的变通方法或是妥协。 同样的,为每个目标平台定下最低要求。并为你的研发及QA团队寻找到多个设备,因为在开发过程中将会用到不少的目标设备。这样你就可以迅速地测量并调整现实的性能表现和每一帧的预算,并且可以在整个开发过程中保持对它们的监控。 定下内存和性能预算 当你建立好了目标配置需求及支持的功能,确定好内存和性能的预算。这可能会很棘手,且在开发过程中你可能会需要重新定义和调整它们,但是带着一个合理的计划开工要比没有任何计划并将你喜欢的东西一股脑儿丢进你的项目中去要好得多。 一开始,定下你的目标帧数和理想的CPU性能预算。对于移动平台,别忘了过热可能会发生并降低CPU和GPU的频率,所以在你的规划中为它们预留空间。 从你的CPU预算开始,尝试去决定对不同系统需求,渲染、特效、核心逻辑等等,你想花费多长时间。 内存预算可能会很难决定。Asset是内存开销大户,而且是你(作为开发者)无法控制的。举例来说,你打算给asset花多少内存?贴图、模型和音效将会吃掉一大部分,而且你不小心的话很容易失去控制。避免过大的贴图,根据它们在屏幕上可视的大小以及目标平台的分辨率将它们大小控制在合适的范围。类似的,根据情况确保模型有着合适的顶点和三角形数。一个只在远处出现的模型不需要高精度的模型。 最后,思考一下对于你项目中的系统你可以给多少内存。举例来讲,你可能实现了一个特定的系统来预先计算大量的数据以减少每次更新时CPU的计算量,但这合理吗?这就是那个消耗了不成比例巨大内存的系统吗?或许它是对于性能来讲最重要的系统,因而这些代价都是值得的。这都是你需要规划好的问题。 建立打包和QA的步骤 建立好一个打包和QA的步骤至关重要。本地打包和测试在某个时间点前都十分有用,但这同时也很消耗时间及容易出错。对于这个问题有多种解决方案可以供你考虑(例,Jenkins就很流行)。你可以选择配置自己的打包专门用机,或者使用一种云服务来减小维护自己的打包机器的开销。你也可以考虑Unity Teams的Cloud Build功能。花点时间评估并选择一种适合自己需求的方案。 先计划好如何将功能发布到你的发布版本是个好主意。与版本控制一起,考虑你想怎么样打包和验证你的开发分支。作为打包过程中一部分的自动化测试可以找到许多问题,但不是全部问题。如果你确实有自动化测试运行,记得收集测试结果,以便在不同版本间比较测试的表现。这将帮助你更快地发现退化。你也需要在你的流程中加进一些手动质量检测。只要它们被验证完了就可以合并分支到发布版本中。 ? 考虑从头再来 在完成你项目的原型之后,认真地考虑是否要从头开始你的研发过程。在原型阶段作出的决策通常以速度为优先,且很有可能原型项目中包含了许多的“hack”因而并不是一个适合你开展工作的牢固基础。 大部分的开发者都想把他们的时间花在创造和生产上,而不是持久地与工作流程的毛病搏斗。然而,在开发过程中糟糕的选择可能会导致低效和团队的失误,影响最终产品的质量。要减少这种情况,对于常见的任务找方法以精简优化它并使其更健壮。这将使你的团队因问题导致的损失的减到最少。 自动化重复的手动工作 重复化的手动工作往往是自动化(例如,通过自定义脚本或是编辑器插件)的首要选择。一段相对较小的时间和工作量可以转化成整个团队在整个项目生命周期中累计节省的大量时间。自动化工作也剔除了人为失误的风险。 特别是,确保你项目的打包过程是全自动并可以一键完成的,要么是在本地要么是在一个Continuous Integration服务器上。 使用版本控制 所有的开发人员都应该使用一种版本控制,Unity也有多种内置的解决方案。 确保你项目的Editor Setting中的Asset Serialization Mode设为了Force Text,这应该就是默认的值。 Unity同样也有一个内置的专门为合并场景和Prefab的YAML(一种人类可理解,数据序列化的语言)工具。确保把这个同样也设置好。更多信息,请参见这里SmartMerge。 如果你的版本控制方案支持提交hook(例如,Git),你可以用它来执行某些特定的标准。更多信息请参见Unity Git Hooks。 你应该将所有开发工作和你的主分支隔离开来以保证你的项目总是有一个可以稳定运行的版本。使用分支和标签来管理milestone及发布。 对团队执行一个良好的提交信息规定。清晰、有意义的提交信息将帮助在开发过程中定位问题,而空白或无意义的信息只会平添麻烦。 最后,优秀的版本控制可以协助你迅速找到一个问题是什么时候开始出现的。以Git为例,它有一个bisect功能让你选择一个好的版本和一个有问题的版本然后使用“分而治之”的方法来检查中间版本并测试和标记它们是好或坏。花些时间学习你的版本控制系统有哪些功能并找到那些可能在开发过程中有用的。 利用好Cache Server 在Unity编辑器中切换目标平台,尤其是大型项目,可能会非常慢,所以我们推荐使用Unity Cache Server。如果你需要多项目或版本的Unity的支持,你可以运行多个cache server,乃至使用不同的端口。 小心插件 如果你的项目包含了大量的插件和第三方库,因为许多插件都内置了测试用资源及脚本,很有可能这些未被使用的资源被一起打包进了你的游戏。 如果你正在使用Asset Store的资源,检查哪些依赖被添加进了你的项目。举例来讲,你可能会惊讶地发现你的项目中有多种不同的JSON库。 最后,将你不需要的插件中的资源剔除,以及项目原型阶段留下的那些旧资源及脚本。 注重于Scene和Prefab的合作 思考清楚你打算让团队如何合作相当重要。大型、单一的Unity Scene并不适合团队工作。我们建议你将关卡拆分成多个相对较小的场景以方便美术和设计师在最小化冲突的情况下共同制作同一个关卡。在运行时,你的项目可以通过SceneManager.LoadSceneAsync()接口以及传进mode=LoadSceneMode.Additive来叠加地加载场景。 Unity 2018.3和之后的版本有Improved Prefabs可以支持Prefab的嵌套。 这可以允许将Prefab内容拆解成更小的分开的对象以让不同的团队成员在最小化冲突的风险下独立地工作。就算如此, 也会出现团队成员需要对同一个资源开展工作的情况出现。确保你们对如何处理这个问题达成了共识。这个可能仅仅需要一个内部沟通政策从而团队成员通过一个Slack频道、邮件等相互通知。如果你的工作流程支持的话,你也可以使用版本控制系统的文件check-in/check-out机制来解决这个问题。 经常调试你的项目 别让你项目的问题累积起来——试着频繁调试你的项目,而不是仅在项目计划的后期或者说当你的项目表现出了性能上的问题时。对你的项目典型的“性能表现”有个良好的感觉可以帮助你更容易地发现性能问题。如果你看到了一个新的问题,请尽快调查。 一些重要的调试技巧 Unity工具 Unity自带的调试工具通常需要在你项目的开发版本运行。所以尽管性能表现和最终的非开发版本不完全一致,它应该可以提供一个相对较好的全局表现,只要你选择了Release而不是Debug设置。 ? 用Unity Profiler查看项目的关键部分 经常用Unity Profiler来查看你项目的关键部分。来查看你项目的关键部分。 在你的脚本中增加有意义的Unity Profiler采样器来在不用进行Deep Profiling的情况下为你提供更直观的信息。Deep Profiling会极大影响性能而且只在Unity编辑器中或者是支持Just-In-Time Mono编译的平台(例如,Windows,macOS和Android)运行。 别忘了除了可以重新排序Profiler工具的每条记录(比如CPU、GPU、物理等)你还可以添加和移除它们。在Unity 2018.3和之后的版本中,移除那些目前不需要的记录将减小在目标平台上运行时CPU的占用。在以前的Unity版本中,在运行时所有调试信息都会被收集,因而增加了Profiler的性能消耗。 在Profiler的Hierarchy视图中,按Total列来排序以定位CPU消耗最大的区域。这将帮助你集中到需要调查的部分。 类似的,按GC Alloc列来排序以揭露产生托管内存分配的区域。以尽可能减小内存分配为目标,尤其是那些经常甚至于每帧都会发生的,并集中解决可能导致托管内存堆迅速增长并触发垃圾回复的内存分配高峰。将托管内存堆(managed heap)的大小(在Profiler的Memory记录中显示为Mono)保持的尽量地小。因为使用的内存越多,它就会越发碎片化,从而导致垃圾回收极其昂贵。 不像只注重于Unity主线程的Hierarchy视图,Profiler的Timeline视图将提供给你一个宝贵的关于多个线程的总览,包括Unity主线程和Rendering线程,Job System线程和用户线程(如果添加了合适的Profiler采样器)。 用Profiler Analyzer来对付退化测试(regression testing) Profile Analyzer可以让你从Unity Profiler中导入数据——或是目前捕获的数据或是保存在文件中的先前的记录——并允许你进行多种分析。除了可以看到分解成平均值、中位数和峰值消耗的调试标记,你还可以比较数据集。这相当有用,比如说在退化测试中当你比较改变前后收集到的数据。 记录并可视化内存消耗 Memory Profiler(可以在Package Manager中的Preview package里找到)是一个可以记录并可视化部分(不是全部)应用的内存使用的强大工具。它的Tree Map视图对于立即可视化常见资源类型的内存消耗,如贴图和模型,以及其他的内存管理类型如字符串和项目特有的类型,特别有用。 检查资源消耗的区域以排查潜在的问题。比如说,异常巨大的贴图可能是错误的导入设置或过高的分辨率所导致的。重复的资源也可能在这里被发现。不同资源有相同的名字是可能的,但是相同名字和相同大小的多个资源就可能是重复的资源且需要调查清楚。错误的AssetBundle分配是该问题潜在的一个原因。 检查渲染和批合并的流程 Frame Debugger工具对于检查渲染流程和批合并的部分相当有用。比如说该工具将告诉你为什么一个合并被打断了,这为你优化你的内容指明了方向。 当你看到一帧是如何创建起来的,其他的问题可能也会显露出来。比如说多次渲染相同的内容(例,在实际项目中重复的摄像机曾被发现)以及渲染完全被遮挡了的内容(例,在一个全屏幕2D UI后继续渲染一个3D场景)。 平台/供应商特有的工具 尽管Unity的调试工具提供了海量的功能,花费时间学习高效地使用你目标平台的原生调试工具也非常值得。 例如: 这些工具包提供了更加强大的调试选项,比如说基于采样和基于指令的CPU调试,完全原生的内存调试,和包括shader调试在内的GPU调试。通常你将对你项目的非开发版本来使用这些工具。 你将可以测量所有CPU核心、线程和函数的性能,而不只是那些有Unity Profiler标记的。 内存调试(例,在iOS中通过Instruments' Allocation和VM Tracker工具)能揭露不会在Unity的Memory Profiler中显示的内存大户,例如第三方插件的原生内存调用。 资源管线非常重要。你项目的大部分内存占用将来自贴图、模型以及音效这些资源,因此非最佳的设置将会让你流很多血。 为了避免这种情况,建立好一个美术资源的工作流程,来将美术资源制作成正确的规格至关重要。如果可能的话,从一开始就带一个经验丰富的技术美术一起讨论,让他帮助定义这个步骤。 首先,为你将使用的格式和规格定下清晰的指导方针。 你的项目中所有的资源都正确地设置的导入设置是非常重要的。确保你的团队明白他们工作的资源的设置,并执行规定来确保你所有的资源有一致的设置。 同样的,不要对所有平台仅仅使用默认的设置。使用平台特定的设置来优化资源(例如设置不同的最大分辨率或者是音频质量)。 你可以考虑使用AssetPostprocessor API来自动设置好新资源的导入设置,就像这个项目。 相关阅读:美术资源最佳实践指南 正确地设置好贴图的导入设置 贴图通常是所有资源里面消耗内存最多的,所以请确保你的导入设置是正确的。 请永远不要勾选Read/Write Enabled选项,除非你真的需要在脚本中读取像素信息。该选项将在CPU内存和GPU内存中各保存一个副本,因而将总体的内存开销翻倍。好消息是,你可以通过Texture2D.Apply() API然后定义参数makeNoLongerReadable=false来强行使贴图资源丢弃CPU内存上的副本。 当需要mipmap的时候才启用它。通常来讲在3D场景中使用的贴图需要mipmap,但在2D中则没有这个需求。当不需要这个选项却仍勾选它的话会增加约1/3的贴图内存占用。 能用压缩就用,尽管不是所有贴图都能保持足够的视觉上的清晰度,尤其是UI贴图。了解清楚对于你的目标平台可选压缩格式的优缺点,并作出明智的选择。举例来讲,在iOS平台上用ASTC通常最终的效果比PVRT更好,但是这个格式不被没有A8或更新的芯片的低端设备支持。有些开发者选择将不同压缩版本的资源放进项目,允许他们对特定设备使用最高质量的资源。 尽量多使用Sprite Atlas来将贴图组合。这将改善批合并以及减少draw call数目。根据你使用的Unity版本,可以使用Unity SpritePacker或Unity SpriteAtlas或者类似Texture Packer这种第三方的工具来进行这个操作。 通过禁用Mesh选项来收复内存 同理,当你需要通过脚本来读取网格数据的时候才勾选Read/Write Enabled选项。该选项直到Unity 2019.3之前都是默认勾选的,而且就留着让它保持勾选的状态相当常见。对于许多项目你可以通过禁用该选项收复内存的失地。 如果你的项目用到了不同的模型文件(例如FBX)来导入可见的网格和动画,请确保将源文件中的网格丢弃。否则,这些网格数据仍会被打包进最终的输出中,浪费内存。 为音频选择最佳的压缩格式 对于大部分的Audio Clip,Load Type设置中默认为Compressed In Memory会比较好。确保你为每一个平台都选择了合适的压缩格式。主机有其自己的自定义格式,而其他平台Vorbis是一个不错的选择。在移动平台上,因为Unity并不支持硬件解压缩,所以在iOS上使用MP3并没有什么优势。 为每个目标平台选择合适的采样率。举例来说,移动设备上的一段短音效不应超过22050Hz,而实际上大部分的音效都可以在最终效果差别极其细微的情况下用一个更低的数值。 确保较长的音乐或环境音效的Load Type设置为Streaming,不然整个资源会一次性地加载进内存中。 将Load Type设置为Decompress On Load会占用一定的CPU及内存来将音频解压缩成原生的16-bit PCM音频数据。该选项通常只对于经常同时发生的短音效,如脚步声或剑相撞声,有必要使用。 当可能的时候,使用原始(无损)未压缩的WAV文件作为你的资源。如果你使用压缩格式(譬如MP3或Vorbis)的音频文件,Unity会解压缩它并在打包过程中再次压缩。这两次有损的转换步骤会降低最终的音频质量。 如果你计划在你的项目中将声音放置在3D空间中,你应该将它们改为单通道或者打开Force To Mono设置。这是因为放置在某个位置的多通道音频在运行中会被压缩成单通道,因而增加了CPU的消耗和内存的开销。 用AssetBundles,而不是Resource文件夹 使用AssetBundles而不是将资源一股脑地放在Resource文件夹内。放在Resource文件夹中的资源会被打包进一个内部的AssetBundle中,接着这些的文件头信息会在启动时加载。因此将大量资源放进Resource文件夹的结果就是启动时间变长。 为了避免重复的资源,显式地将所有资源放进AssetBundles中,尤其是那些有依赖的。比如,假设有两个材质用了同一张贴图。如果这张贴图没有被放进一个AssetBundle中而那两个材质被放进了两个不同的AssetBundle,那么这张贴图将会被复制一份然后分别随着那两个材质放进AssetBundle。显式地将该贴图放进AssetBundle来避免这种情况的发生。 你可以使用AssetBundle Brower工具来设置和追踪AssetBundle中的资源和依赖关系,AssetBundle Analyzer工具来高亮显示重复的资源以及潜在的非最佳设置。 为把资源整合进AssetBundle中建立你自己的解决方案,因为放之四海而皆准的解决方案并不存在。许多人选择按逻辑来组合AssetBundle,例如,对于一个赛车游戏,你可以将每款车型所用到的所有资源放入一个单独的AssetBundle中。 但是,对于那些支持patching的平台要小心。因为压缩算法的应用,对资源一个很小变更都会导致整个AssetBundle的二进制数据改变。这意味着不能生成一个高效的patch delta。因此,如果你的项目用了很小数目的大AssetBundle,这将会成为一个大问题。为了patching,使用相对较小的AssetBundle而不是仅使用几个大的。 通过遵守这些最佳实践以及作出明智的架构决策,你将确保更高的团队效率和游戏发售后更好的用户体验。 相关阅读:如何获得更好的编写脚本的体验 避免抽象类 过度设计和抽象的代码可能会令人难以理解,尤其是你团队的新进成员,而且这通常会让分析和讨论变更更加困难。这类型的代码通常会促生更多代码,导致更长的编译时间(包括有更多IL去翻译的IL2CPP build),而且最终的代码可能会更慢。 理解Unity Player Loop 确保你对Unity的帧(玩家)循环有着足够的理解。例如,知道Awake,OnEnable,Update和其他函数是什么时候被调用的相当重要。你可以在Unity文档中找到更多信息。 Update和FixedUpdate之间的差别极其重要。FixedUpdate方法被项目的Fixed Timestep值控制。该值默认为0.02(50Hz)。这意味着Unity保证FixedUpdate方法每秒调用50次,因而一帧中有多次调用是可能的。如果你的帧数下降了,这个问题可能会更加严重,因为一帧中FixedUpdate调用的次数变多了。这将可能导致我们平时称之为“死亡螺旋”的恶性循环发生,因为它有时会展现出严重故障的形态。 物理系统更新是FixedUpdate是一部分,所以有大量物理内容的游戏可能会在这个地方挣扎。一些项目也使用FixedUpdate来运行各种游戏系统,因此请小心地检查及避免这类性能问题的发生。由于这些原因,我们强烈推荐你将项目的Fixed Timestep值设置成与你的目标帧数高度接近的数值。 选择合适的帧数 选择一个合适的目标帧数。举例来讲,移动项目常常需要在流畅的帧数和电池消耗及过热降频之间取得一个平衡。以60 FPS运行一个大量占用CPU和/或GPU资源的游戏会导致更短的续航时间和更快的过热。对于大部分项目来说,以30 FPS为目标是一个完全合情合理的妥协。你也可以考虑通过在运行中修改Application.targetFrameRate属性动态调整帧数。 在Unity 2019.3 beta开始支持的全新的On-Demand Rendering功能可以让你降低渲染的频率同时保证其他系统,如输入系统,不受影响。 在脚本或动画中没有将帧率考虑进去很常见。不要假设更新时间是一个常量,在Update中用Time.deltaTime并在FixedUpdate中用Time.fixedDeltaTime。 避免同步加载 当加载场景或是资源时常常会出现性能曲线上的高峰,这通常是因为把加载放在Unity主线程中同步执行。因此,将你的游戏设计成健壮的异步加载来避免这些性能高峰。使用AssetBundle.LoadFromFileAsync()和AssetBundle.LoadAssetAsync()而不是AssetBundle.LoadFromFile()和AssetBundle.LoadAsset()。 将你的项目设计成异步的还有其他的好处。用户交互可以保持流畅。与服务器的认证和交换过程可以与场景和资源的加载同时进行,因而减少整体的启动和加载时间。完全异步的设计还意味着将来将你的项目移植到全新的Addressable Asset System会更加简单。 使用预分配对象池 当对象频繁创建和摧毁的时候(合适例子是子弹或是NPC),使用回收重用的预分配对象池。尽管每次重用重置对象的特定组件可能会消耗一定的CPU,这仍然比新建一个对象要节省性能。这次方式同样极大地减少了你项目中托管内存分配的次数。 尽可能减少使用标准behavior方法 所有自定义的行为都继承于一个定义了Update()、Awake()、Start()以及其他方法的抽象类。如果一个行为不需要用到这些方法(完整的列表可以在Unity官方文档中找到),请完全移除它而不是留着一个空函数体。否则这个空函数将仍被Unity调用。这些方法会导致小量的CPU开销,主要是因为从原生代码(C++)调用托管代码(C#)的消耗。 这对于Update()方法来讲特别麻烦。如果你的项目里有大量对象都有Update()方法,这些CPU的开销可能会上升到对性能有影响的地步。考虑使用“管理者模式”:一个或多个管理者类实现一个Update()方法来负责所有对象的更新。这会极大减少原生代码和托管代码之间的通信次数。更多细节请看这篇博客文章。 也一样决定你项目中那些系统需要每帧更新。游戏系统通常可以运行在更低的频率,轮流更新。一个简单的例子就是两个系统在每两帧交替更新。 我们亦推荐使用时间分片,既一个负责大量对象的系统将更新工作分摊到多个帧中,在每一帧中仅更新一部分对象。这种设计同样可以帮助减少CPU负担。 这个更高级的形态可能是你实现一个复杂的“更新预算管理系统”。你项目中的各个系统都被分配了一个每帧最大的时间预算,然后每个系统实现一个基于标准接口的管理类来在给定时间内执行尽可能多的工作。这个方法可以在整个项目的生命周期中非常好地帮助管理CPU的高峰负担。遵循这种设计模式的系统也可以变得更加灵活。 记得缓存昂贵的API结果 尽可能地缓存数据。常见的API调用如GameObject.Find(),GameObject.GetComponent()以及存取Camera.main可能会非常昂贵,所以避免在Update()方法中调用它们。正确的做法是在Start()中调用它们并保存调用的结果。 避免运行中的字符串操作 避免在运行中执行包括连接在内的字符串操作。这些操作将导致大量托管内存分配,从而导致垃圾回收的高峰。只有在字符串确实改变了的情况下才重新生成字符串(例如玩家得分),而不是每帧都更新。你也可以使用StringBuilder类来显著减少内存分配的次数。 避免不必要的debug日志 非必要的debug日志经常会导致项目性能的高峰。像Debug.Log()这类API会继续产生日志,甚至是在非开发build中,这往往使开发者大吃一惊。为了避免这种情况,请考虑将这些API像Debug.Log()的调用封装进你自己的类中,在方法上使用Conditional属性[Conditional("ENABLE_LOGS")]。如果没有定义这个Conditional的属性,那么这个方法和它的所有调用都会被丢弃。 不要在重点代码部分使用LINQ查询 尽管因为其强大的功能和易用性,使用LINQ查询很有诱惑力,请避免在关键部分(例如,常规更新)中使用它们。因为它们可能会生成大量内存分配以及占用大量CPU资源。如果你必须要使用它们,保持警惕并限制它们只在偶尔的情况下使用,譬如关卡初始化,只要它们不造成不必要的CPU高峰。 用不分配内存的API Unity有一些API会产生托管内存分配,比如Component.GetComponents()。像这种返回一个数组的API是在内部分配内存的。有时候它们会有不产生托管内存分配的替代者,这时永远要使用不产生托管内存分配的。许多Physics API有全新的不产生托管内存分配的替代品,例如,用Physics.RaycastNonAlloc()而不是Physics.RaycastAll()。 避免静态数据解析 项目经常会处理存储在像JSON或XML这种可读格式文件里的数据。这不仅从服务器下载的数据中很常见,在处理内置静态数据中也很常见。这类解析可能会很慢且往往产生大量托管内存分配。正确的做法是使用ScriptableObject以及自定义编辑器工具来处理游戏中内置的静态数据。 相关阅读:用Scriptable Object来架构你游戏的3个好办法 主要因为在一帧中可能多次调用FixedUpdate(),在游戏中物理系统往往过分消耗性能。然而,你也需要注意其他的潜在可能影响性能的问题。 当可能时,启用在Player Settings中的Prebaked Collision Meshes选项来在打包过程中生成运行中使用的物理网格数据。否则,这些数据将在加载资源时生成。且拥有大量物理网格的对象会在生成中占用Unity主线程的大量CPU资源。 Mesh Collider的消耗可能会很大,因此根据实际情况使用一个或多个简单的内置碰撞体来近似原来复杂的形状。 设置 考虑禁用自Unity 2017开始支持并一直默认开启的Auto Sync Transform选项,以加强向后兼容性。该选项将确保自动化变换任何修改并立即同步更新其内部的Physics对象。然而,在Physics模拟进入下一帧之前将这完成并不总很重要,而它却占用了一帧中大量的CPU时间。禁用该选项将推迟进行同步时间但总体来说节省一定的CPU时间。 如果你使用了碰撞回调,请启用Reuse Collision Callback选项。这将在回调中重用一个内部Collision对象以避免在每次回调中分配内存。同样的,在使用回调函数的时候请小心不要在其中做复杂的计算。因为在大量碰撞事件的复杂场景这些开销将会快速叠加。在你的回调函数中添加Unity Profiler标记可以让它们可见并让你更容易追踪判断它们是否是性能问题。 最后,确保你的Layer Collision Matrix是最优的,既只有需要碰撞的层被勾选。 因为开发者经常喜欢大量使用Animator,在项目中动画这一特性往往惊人的昂贵。 Animator主要为人形角色所设计的,但经常被用来制作单一一个数值的动画(例如,一个UI元素的alpha通道)。尽管由于其状态机流程使用Animator很方便,它实际上相对比较低效。在内部测试中的结果显示,运行在如低端iPhone 4S这样的设备上时,Animator的性能在有约400条曲线时才胜过Legacy Animation。 对于更简单的使用例(比如改变一个alpha值或是大小),考虑使用更轻量的实现方式如自己实现一个功能类或是使用一个类似DOTween的第三方库。 最后,如果你是手动更新Animator的请小心,因为它们通常是使用Unity的Job System并行处理的,手动更新会把它们强制放在主线程中执行。 我们建议使用GPU调试来显示顶点、片段和计算着色器占用的GPU性能。这可以让你调查最昂贵的绘制调用并找到最昂贵的着色器,提供了大量的潜在优化可能。 相关阅读: 小心overdraw和alpha blending 通常移动平台会被alpha blending和overdraw严重影响。大量的GPU渲染时间被大面积但很难注意到的overlay或是有大量零alpha像素的多层alpha-blended sprites特效占用的情况并不少见。 也避免绘制不必要的透明图片。对于那些有大量透明区域的图片(如全屏vignette特效图片),请考虑使用自定义的mesh来避免渲染那些透明像素。 保持shader简洁,精简shader变体 在移动平台上,让着色器越简单越好。用你能实现的最轻量的自定义着色器,而不是用Standard着色器。对于低端的目标平台,使用简化版本的特效或者直接禁用它。 请试着将着色器变体数量控制在最低水平,鉴于大量的着色器变体会影响性能以及消耗大量运行时内存。 不要依赖于大量Camera组件 请避免使用多于你实际需求的Unity Camera组件。举例来讲,现在不难见到项目使用多个摄像机来创建UI层。无论是否做了有意义的工作,每一个Camera组件都会造成一定的开销。在性能强大的目标平台上这可能微不足道,但是在低端或移动平台上每个Camera组件可能消耗最高1ms的CPU时间。 考量静态和动态合并 对共享同一个材质的环境网格启用Static Batching。这允许Unity合并它们以极大地减少绘制调用数量及渲染状态变更,同时可以利用对象剔除。 通过调试来决定你的项目是否在使用Dynamic Batching时表现更好,通常情况下都不是。对象足够相似并必须符合严格且相对简化的条件才可以动态合并。Unity的Frame Debugger可以协助你看到对象未能成功合并的原因。 别忘了正向渲染和LOD 当你使用正向渲染(forward rendering)的时候避免使用太多动态光源。每一个动态光源都会为每个受光的物体增加一个新的渲染步骤。 也别忘了可以使用Level of Detail(LOD)的时候就用。当物体移动到远处的时候,使用简化的材质着色器与模型以大幅改善GPU的表现。 Unity UI(也被称为UGUI)经常是项目性能问题的来源。更多细节请查阅Unity UI优化贴士。 考虑使用多分辨率和宽高比 Unity UI让建立一个可以适应不同分辨率和宽高比屏幕调整位置和缩放UI很简单。然而,一种设计不总适合所有平台,所以创建多种版本的UI(或者说部分UI)来让每个设备上都有最佳的体验。 务必要在各种支持的设备上测试你的UI以确保用户体验是最佳且一致的。 避免使用少量的Canvas 别将你的UI元素放在一个或者几个大Canvas中。每个Canvas都对其所有元素维护一个网格。当一个元素改变的时候,这个mesh会被重新创建。 将UI元素放入不同的Canvas中,最好是根据其更新频率来分组。将动态元素和静态元素分开将避免重建静态网格数据的消耗。 注意Layout Group Layout Group是另一个常见的性能问题源,尤其是嵌套使用它们的时候。当在Layout Group中的UI Graphics组件改变了的时候,例如说当ScrollRect移动的时候,UGUI会递归向上查找场景的层级直到找到一个没有组件父母节点。该layout和里面的所有东西随后都会被重建。 尽量避免使用Layout Groups,尤其是当你的内容并非动态的时候。为避免Layout Group仅仅用来初始化随后不会改变的布局内容,考虑添加一些自定义代码来在内容初始化之后禁用那些Layout Group组件。 List和Grid视图可能会很昂贵 List和Grid视图是另一个常见的UI模式(例,背包或商店界面)。在这种情况下,当可能有上百个物品而一小部分可见,请勿为所有物品创建UI元素,那样的会非常昂贵。请实现一种模式以重用元素并在它们移动出一边时将它们放回另一边上。一位Unity工程师已经提供了一个Github项目使用例。 避免大量重叠的元素 由多层重叠的元素构成的UI并不少见。一个合适的例子可能是卡牌游戏中的一个卡片Prefab。尽管这种方式可以允许许多设计上的自由度,大量的像素overdraw可能会极大的影响性能。它甚至可能导致更多次数的绘制分批。请研判你是否能将多个层级元素合成为更少(乃至一个)的元素。 思考你如何使用Mask和RectMask2D组件 Mask和RectMask2D组件在UI中常常用到。Mask利用渲染目标的模板缓冲来决定是否绘制像素,几乎将成本全部放在GPU上。RectMask2D在CPU上运行边界检查来丢弃在蒙版外的元素。拥有大量RectMask2D组件的复杂的UI,尤其是嵌套时,可能会占用可观的CPU性能来进行边界检查。小心别过多使用RectMask2D组件。或者是你项目GPU负载低于CPU负载时,考虑切换到Mask组件以平衡总体的负载。 组合你的UI贴图以改善合批 确保将UI贴图尽可能地合成成一张大贴图以改善合批。将逻辑上属同一类的贴图合成一张大贴图合情合理,但也要小心大贴图不要过大以及/或者过于稀疏地填充。这是一个常见的内存浪费来源。 同时也要确保可以压缩大贴图的时候将其压缩。通常来讲UI贴图是无需压缩的,因为压缩会产生瑕疵,但这也取决于实际情况。 在绝大部分情况下,UI贴图是不需要mipmap的。所以请确保其在Import Setting中是禁用的,除非你确实需要它(比如说世界空间中的UI)。 当你添加一个新的UI窗口或屏幕时请小心 当添加一个新的UI窗口或是屏幕时经常会引发项目中的问题。这有许多潜在的原因(例如,因为根据需求加载资源以及实例化一个有大量UI组件复杂结构的纯粹开销)。 也尝试减少UI的复杂程度,考虑缓存相对来讲经常使用的UI组件。禁用并启用它然而不是每次都摧毁并重实例化它。 当不需要时禁用Raycast Target 记得禁用UI Graphic元素的Raycast Target选项,如果它们不需要接受输入事件。许多UI元素都不需要接受输入事件,比如在按钮上文字或者不可交互的图片。然而,UI Graphic组件的Raycast Target选项时默认开启的。复杂的UI可能会有大量非必须的Raycast Target,所以禁用它们可能会节省不少的CPU处理时间。 我们希望本文中的最佳实践和贴士可以帮助你的项目建立一个健壮的结构并且你使用正确的工具和设计、开发、测试和发行的工作流程。当你需要更进一步以及来自最后期限的压力增大,请务必去寻找其他公开的Unity资料。 ? 更多信息 你可以在Unity Blog,推特的#unitytips标签,Unity社区论坛,Unity Learn上找到更多优化技巧,最佳实践和新闻。 ?♂? 联系Unity ISS 需要个性化的服务?考虑一下Unity Integrated Success Services。ISS不只是一个支援包。有着一位专门的Developer Relations Manager(DRM),一位Unity专家迅速融入你的团队,你的项目将得到极大地加强。你的DRM将确保提供给你专门的技术和操作专家以解决问题和保证你的项目发售前后都运行流畅。请填写我们的联系表格以联络我们。 从18年12月接手在基于x86平台的边缘计算设备上进行取流解码的工作至今,已有数月。笔者还记得当初对流媒体、视频、帧、图像等概念完全云里雾里,慢慢跟着项目一步步学习走过来,受益良多,以这篇文章励志作为后续继续学习的里程碑吧! 本文将介绍的是: 2019年4月8日首次完成该文章,内容包括: 2019年9月7日进行二次修改,修改内容如下: 相信所有人对视频一定不陌生,平时也一定经常在各大视频网站(如腾讯视频、哔哩哔哩)浏览,甚至偶尔也会把视频缓存到本地,保存成.mkv,.avi文件之类啦。前者是我们常说的『网络流媒体』,后者是『本地视频文件』。提到这里,两个问题来了: 介绍第一个问题之前,必须引入一个名词『视频封装格式』,简称『视频格式』,也称为『容器』。有的说法还要区分是视频文件格式和视频封装格式,本文统一称『视频封装格式』。 问题1:本地视频文件常见有MP4、MKV、AVI等,这些都是什么?有什么区别? 首先,MP4、AVI、MKV都是本地视频文件的后缀,在windows系统下,用于提示操作系统应该采用哪个应用程序打开。而在流媒体领域,这些都被称为『视频封装格式』,因为除了音视频流之外,它们还包含了一些辅助信息以及组织视音频的方式。不同格式的视频在不同平台上用户体验不同,很大原因在于对视音频的组织方式带来的差异。笔者以为百度百科上的解释蛮通俗易懂的(维基百科的说法不够直白): 简言之,视频格式规定了和播放器的通信协议。 其次,笔者最近准备开始深入研究MP4、AVI、MKV等内部原理,主要是对视音频的组织方式,比如在播放视频的时候,我们可以选择国语、粤语、英语等各种语言,这就意味着这段视音频中包括了多个音频流。【给自己留个坑吧。】 最后,笔者推荐一篇非常棒的博客:视频文件格式知多少,汇总的非常全。 问题1引申:对要做视音频处理的开发们来说,接触MP4、MKV、AVI等各种格式视音频文件时,有什么需要注意的吗? 视音频处理可以延展出很多领域,包括解码、编码、过滤、增强处理等等。笔者目前只在解码领域探索,答案是:对于解码而言,没有区别。其他领域暂不清楚。 『视频封装格式』,是在编码的视音频基础上进行一次“包装”,添加与播放相关的协议数据(这个是笔者的认知,如有表述不准确,欢迎批评指正)。目前主流开源的框架,在“解包装”工作上做的已经非常成熟了,如 接下来,介绍第二个问题,笔者再引入名词『视频协议』,也有说法认为『视频协议』也属于『视频封装格式』。 问题2:在腾讯视频、哔哩哔哩网上看的视频,与本地播放的MP4、MKV、AVI文件,有什么区别? 『视频协议』是针对网络流媒体而言的,也就是只有在有网络时通过浏览器或者移动端APP才能看到的视频,目前常见的协议有RTSP、RTMP、HLS、HTTP等。笔者短暂地接触过GStreamer开发,在连接到RSTP视频时,发现除了视音频流和metadata之外,还携带了播放的信令。 也有文章会把『视频协议』归入『视频封装格式』。笔者看来,这么分类也有其道理:『视频协议』和『视频封装格式』都同时携带了视音频和metadata,以及协议/格式需要的其他信息。以 剥开『视频封装格式』和『视频协议』的外壳,接下来了解视音频流本身,这才是流媒体领域中真正的主角。本文仅介绍视频流。 就视频流而言,相信大家平时一定经常听到类似“h264码流”、“yuv流”、“编码流”、“解码流”,“原始流”、“裸流”,“压缩后的流”或者“未压缩的流”等等。归纳而言,提到『视频流』的时候,一定只有两种形式: 总结出现的名称,“h264码流”、“编码流”、“压缩后的流”是压缩/编码后的视频流;而“yuv流”、“解码流”、“未压缩的流”则是未经压缩/编码的视频流。“裸流”是一个具有歧义的词,是上下文内容,既可以是前者,也可以是后者。 因此,如果以后阅读任何流媒体相关的文章时,看到『视频流』都应该搞清楚,这究竟是编码/压缩的,还是没有。在生活中,接触到的视频文件绝大部分都是编码/压缩后的;在网络传输场景中,绝大部分也是编码/压缩后的。只有在视频播放时,观众观赏到的时一帧帧被『转码』为『RGB』的解码后视频流。 编码/压缩在流媒体领域是一项非常重要的技术:从『H264码流』到『YUV流』的过程称为解码,反之称为编码。 流媒体领域,『流』很重要,『流』的基本元素『帧』同样重要。原因在于:对于视频编码/压缩而言,它的核心是采用尽量小的空间存储一组时间上连续的帧数据;而对于视频解码而言,就是把被编码/压缩后的一组帧数据尽量恢复成原来的样子。能够被100%恢复的编码/压缩算法称为无损压缩,反之称为有损压缩(虽然无损压缩是最理想的,但是在很多实际场景中为了追求高压缩率,比如为了减小网络带宽压力,常常不得不选择有损压缩)。由此可见,『帧』是视频流媒体领域的核心。接下来,一起来认识什么是『帧』。 『帧』,可以联想成我们平时看到的一幅幅“图像”,只不过我们平时接触的图片是『RGB』格式的,而视频帧通常是『YUV』格式的。既然提到了『RGB』和『YUV』,那么就来了解下帧的格式『YUV』,引出第一个问题: 问题3:帧为什么采用『YUV』格式?『YUV』是什么? 为此,笔者曾经花了很久去了解颜色空间、电视成像的发展史等,整理结论如下: 接下来解释『YUV』是什么,笔者以为,『YUV』是一种广义的概念,在视频领域,当提到『YUV』的时候,往往是以下几个意思: “Y”表示明亮度(Luminance、Luma),“U”和“V”则是色度(Chrominance)、浓度(Chroma)。这里表示的是色彩空间的基,即类似XYZ坐标系的一种色标表示基准,也就是说每一种颜色可以通过三维向量<y^i^,u^i^,v^i^>来表示。与其类似的还有RGB颜色空间、HSV颜色空间等。下图来自How does the YUV color coding work? 随着通信行业的发展,实际应用之多之复杂,导致『YUV』衍生出了一个大家族。接触视频领域的一定听说过YCbCr,甚至还有YPbPr、YIQ等。它们有的已经被时代淘汰,有的现在还在使用。之所以出现『YUV』大家族,完全是因为实际电路系统之间的差异,导致要从『YUV』转到『RGB』空间,实际对应的转化系数是有些许差异的,于是各个部门开始制定各种规范,才有了我们现在看到的『YUV』大家族。 YCbCr是专门针对数字电路而诞生的;YPbPr则是模拟电路。但是,现在是数字时代,所以为了模拟电路而生的YPbPr已经逐渐被淘汰了,而YCbCr还一直发挥着作用。因此现在,YCbCr有时也会被简单地称为/认为『YUV』。 2. 采样率 读者可能听说过“YUV444”,“YUV422”,“YUV420”,到这里可能会纳闷:“YUV不是颜色空间吗?为什么后面还会跟着一串数字?” 因为当你看到YUV后面跟着一串数字的时候,『YUV』已经不再是颜色空间的基的含义了,而是意味着在原始『YUV流』上的采样。 ?图2-1对应YUV444采样,即全采样,图示中可以看出每个像素中的Y\\U\\V通道都保留下来了,一般来说YUV444太大了,因此很少使用。 图2-2对应YUV422采样,这种采样方式是:每个扫描线或者说每行相邻2个像素,只取1个像素的U\\V分量。此外,可以计算出来,每个像素占用的大小为原来的2/3,因此说YUV422是YUV444的2/3大小。 这个时候就有一个问题,在『YUV』转『RGB』时,被抽走了U\\V分量的像素要怎么办呢?做法很简单,就是相邻2个像素的Y分量公用保留着的U\\V分量。 图2-3对应YUV420采样,这种采样方式是:隔行进行YUV422每行采样的办法,即相邻2个像素只取1个像素的U\\V分量;下一行丢弃所有的U\\V分量。此外,可以计算出来,每个像素占用的大小为原来的1/2,因此说YUV420是YUV444的1/2大小。恢复U\\V分量的办法同YUV422,只不过这里是2X2的矩阵共享保留着的U\\V分量。 这种设计办法真的很巧妙!前文提到的"人眼对UV的敏感度最低,因此可以极大比例地压缩UV两个通道的数值",且对于图像而言,相邻的区域像素的色彩、饱和度一般非常接近,因此这种以2X2矩阵为基本单位,只保留1组U\\V分量合情合理。 3. 编码/存储格式 大家肯定还听说过YV12、YU12、NV12、NV21吧,看到这里是不是又纳闷:“后面的数字怎么变成2个了?而且前面的英文字母还变了?” 但是关于上图的『打包格式』,笔者是是有一点疑惑的,大多数的说法是”Y\\U\\V通道交叉存储,相邻的像素尽量打包在一起“,图3-3中U1后面跟着的是U2而不是V1,而且Y\\U\\V的排列方式似乎也不完全是交叉?笔者尝试在网上搜索『打包格式』更多的例子,没有找到特别好的资料,【这里给自己挖一个坑吧】。 接下来,我们继续了解一些帧相关的概念。 常见的帧名词 『帧率』『分辨率』和『码率』三者之间的关系 文章后面又特别强调『分辨率』和『压缩率』对『码率』的影响:高分辨率意味着图片可以包括更多的细节,低压缩率意味着图片压缩损失越少,即失真越少,越清晰。那为什么不特地讨论『帧率』呢?笔者认为原因有二:一个是『帧率』的影响非常直观,每秒帧数增加必然导致数据量增加;另一个是实际应用场景中『帧率』是相对固定的,我们观看的一般视频都在25-30fps之间,现在一些高帧视频是60fps,可见视频『帧率』在实际场景中被讨论的很少。 奇怪的帧名词:1080p和1080i、场 笔者仅仅出于觉得有趣才放上来的,1080p和1080i、场都是相对比较“老”的概念了,在还是CRT电视的时代,显示器显示画面都是靠电子枪一行一行扫描画面才能产生一副完整的图像,这就被称作『场』,后来这个名词也不常使用了,被取代它的是『帧』。【科技在进步,过时的概念、应用都会被新兴的替换,所以真的要不断学习紧跟时代啊!】 1080p和1080i也是『场』同一时期的概念: 既然都是老概念了,那为什么还要再提呢?借用文章1080P和1080i是什么意思?的一段来说: 视频『帧』和编解码密切相关,因此还有不少『帧』的概念是和视频编解码相关的。 视频编解码而衍生的帧名词 I/P/B帧,并不是依据视频帧数据内部的元素的不同来区分的,从解码后的帧本身而言,它们没有任何区别。仅仅是在编码时,对帧处理的方式不同而已。 这个概念在做视音频同步的时候特别重要,尤其是PTS,目前常见的视音频同步的三种策略“同步到音频的PTS”、“同步到视频的PTS”和“同步到系统/外部时钟”,都是基于PTS完成的。 尽管每个概念网上都可以搜到一大堆的资料,但是笔者从一个多媒体开发小白走过来,觉得能有相对系统入门的综合性介绍就会更好了!本文每个地方,都是基于笔者自己的理解,而不是简单地从网上“复制粘贴”过来的,希望能够对大家有所帮助!当然,文章中有不严谨的地方,欢迎留言告知;或者有什么有趣的话题探讨,也欢迎私信留言! 最后,笔者目前在腾讯优图的边缘计算开发小团队,目前我们正在计划开源一款能够适配设备(以边缘设备为主)视觉AI计算落地应用框架-RapidAIoT,内容包括视频取流、AI计算、消息结果上报下发中间件。也欢迎大家咨询了解。 本次为大家带来的是全面优化提高游戏帧数的步骤详解。通常情况下,硬件平台所发挥的性能极限不足以满足体验者对当前游戏的帧数期望时,玩家们一般是通过降低画质的方式令帧数得到缓解提高,这一操作也是最正常不过的了。那如何在不调节游戏画面质量的前提下对游戏进行帧数优化呢? 以Win10操作系统为例。打开开始菜单找到设置选项后打开它后可以发现游戏板块,点击进入。也可以在搜索栏输入“游戏模式设置”进入。 进入之后点击左侧的游戏模式会显示如上图所示的画面,然后我们将游戏模式打开,然后再点击右上角的图形设置选项。 进入图形设置后点击浏览按钮,找到自己想要优化的游戏的根目录点击游戏运行图标进行添加,如果游戏图标存在于桌面上则直接选定桌面图标即可。温馨备注:Steam游戏的默认文件夹路径为:Steam安装的磁盘→Steam文件夹→steamapps文件夹→common文件夹→进入相应的游戏文件夹;Origin游戏的默认文件夹路径为:Origin游戏安装时选择的文件夹→Program Files(x86)文件夹→Origin Games文件夹→进入相应的游戏文件夹。 以三位一体4作为参考,添加了游戏图标后,点击选项,会弹出图形规格方框,选择高性能后点击保存即可。 以上第一个环节是通过调节Win10系统上的游戏设置板块进行优化,这样做的目的可以让玩家在游玩选定游戏后系统可以调用更多的资源来应对游戏运行下的压力需求。接下来,我将为大家详细演示第二个环节,通过NVIDIA控制面板来最大化提高游戏性能。 桌面右键,打开NVIDIA控制面板,点击管理3D设置,选择程序设置后在第一栏的旁边点击添加按钮,点击之后如上图右侧方框所示。玩家可以在框中通过鼠标滚轮查找是否存在希望优化的游戏图标,如果没有则点击浏览后再去选择游戏图标。游戏图标根目录位置参考上面两大游戏平台的路径详解。选定游戏图标后点击添加选定的程序。 如上图所示,在第三个板块指定该程序的设置值下面的框中就是我们需要调节的地方了。注意!选择框中的最后一个选项逐步往上开始表述:虚拟现实预渲染帧数:1、纹理过滤-质量:高性能、纹理过滤-负LOD偏移:允许、纹理过滤-各向异性采样优化:开、纹理过滤-三线性优化:开、着色缓存器:开、电源管理模式:最高性能优先、OpenGL渲染GPU则选择自己的独立显卡。上述就是需要调节的选项了,对于没有说到的选项则不需要调节,默认即可,最后点击应用。 部分玩家可能会有两个疑问:“为什么不选择在全局设置里面调呢?在程序设置调节我还得一个游戏一个游戏的来一遍。“”这些设置会不会让游戏画质降低“?关于这两个问题,想说的是,程序设置可以只针对自己想要优化的游戏,而全局设置则包含了全部游戏及可调节的计算机软件,所以不采取一刀切,选择精准对接的方式会更合适。其二,这些设置在玩家调节使用前都是默认的状态,默认状态下许多选项都是关闭以及是默认建议的存在,这个状态也就是说全以游戏内设置为准,所以对游戏画质下降的影响微乎其微。 除了选择优化帧数这一条路,还能选择让画质更精细的另一条路,突破游戏内最高画质的上限。如图所示,我们将鼠标悬停在红框时,下方绿框的内容就是对该设置的介绍,介绍会让玩家更清晰的了解该设置对应的影响在哪里。同理,我们不仅可以选择高性能来提升帧数,也可以选择高质量来提升画质,比如将各向异性过滤设置为16x等等,这是对于一些不怎么吃配的游戏或者本身硬件性能足够强的前提下寻求更高游戏画面表现的应用场景。 NVIDIA游戏优化内置于NVIDIA GeForce Experience中,玩家只需在桌面右下角的NVIDIA小图标右键即可点击进入。除了更新驱动外,内置的游戏优化选项对部分玩家来说也并不陌生,为什么这里不推荐使用该功能呢?首先该功能通过设置优先级有最佳性能与最佳质量两个优化优化方向,在最佳性能选项下会将画质设置调节的非常低以达到更高帧数;最佳质量选项下会将画质设置调节的更高以达到更精细的画质。 不论是更倾向于哪一种方向,毋庸置疑的是该功能都是通过直接调整游戏内的画质选项来进行优化的。对于选择最佳性能方向的玩家来说还不如直接进游戏将画质调低;对于选择最佳画质方向的玩家来说,虽然优化后游戏帧数基本能够保证60帧,如果玩家有着高于60HZ刷新率的屏幕,那么又会显得有些鸡肋,归根结底就是还不够“聪明“,如果可以让玩家选择一个帧数,然后通过软件对平台性能以及游戏画质压力的预判达到更接近所期望的帧数时才能更好的为玩家服务,这也是其努力的方向。 凡事皆有两面,优点也是存在的。我认为与NVIDIA控制面板中的文字描述所不同的是,NVIDIA游戏优化则是直接通过画面来进行表达。如上图所示,将鼠标悬停在绿框内,而上图的红色箭头处则直接显示该画质选项将对画面带来怎样的影响,文字加上图片的展示无疑是更加一目了然,如果玩家对游戏画质不同选项下带来的差异有兴趣,则可以通过这个方式让自己有所收获。 帧数越高代表着可操作的反应时间越快,在有限的时间内玩家能够看到更多的内容信息无疑是对实际操作有着更多的判断,也能让自己的动作快人一步。如同NVIDIA所主打的“帧”能赢为电竞行业助力一样,电竞领域对反应的要求有着非常高的标准,这也让显示硬件的参数足够亮眼才能达到要求,在玩家群体来看,虽然我们不一定需要那么严苛的标准,但是帧率对玩家影响正在扩大,而且正在从“能玩就行”到“高帧操作”的方向发生转移。 以上就是本次针对游戏优化所带来的全部内容啦!希望能够让各位玩家有所收获。 前言的前言 在讲述万人同屏的技术问题前。一定要先回答一个问题,游戏中万人同屏究竟有什么意义?但这并不是一个问题而是三个问题他们分别是。 1,显卡绘制1万个高质量模型有什么意义? 2,游戏服务器承载1万个玩家互动有什么意义? 3,在客户端或单机中1万个高智能的游戏角色有什么意义? 显卡绘制1万个高质量模型的意义无需多说了。人的眼睛有多挑剔,对显卡性能的要求就有多高。高性能显卡为什么卖的比低性能的贵。用过苹果的人绝对不会再去用诺基亚。一场宏大绚丽的场景可以产生一半的游戏内容。所以好的游戏对显卡性能的追求就像吊丝对女神的向往。 游戏服务器承载1万个玩家互动的意义。玩家的互动是网游的灵魂。游戏的内容总会有被玩尽的时候。一个游戏能存活20年依靠的就是玩家的互动。互动产生的乐趣才是无穷无尽的。人和人之间的斗争才是无穷无尽的。这就是为什么围棋被玩了几千年的原因。在几十个人的战场里玩家被裹挟着只能冲锋!冲锋!再冲锋!但在几百个人的战场里,决定胜负的可能只是偷得一把大门钥匙。 在客户端或单机中1万个高智能游戏角色的意义。网络还是单机游戏不一定都是千篇一律的场景。在随机地图中来一次玩家独特的大冒险。参与到两个部落之间旷日持久的大混战中。让每个玩家拥有自己独特的经历。只有数量庞大的沙盒游戏才能做到。 万人同屏技术与其说是一种技术,不如说是对游戏上限的突破。除非你的游戏完全由剧情组成。否则绚丽的视角,复杂的互动,高随机的可玩性。都是在从技术角度极大扩展了游戏的内容。给了游戏更高更广的设计空间。技术上限的提高代表着更多的可能。也代表着你会做出一款特别的游戏。 前言 3D游戏的万人同屏是非常古老的话题。从网游的传奇,永恒之塔到单机的战争模拟器,骑马砍杀,刺客信条。是什么限制了3D游戏的万人同屏。为什么万人同屏很难做。问题出在哪?怎么去解决?要实现3D游戏的万人同屏,就必须解决以下2个问题。 第一个问题,万人同屏受限于显卡的渲染能力。 第二个问题,万人同屏受限于对1万个人的逻辑处理能力。 渲染的瓶颈 哪么我们先来看第一个问题。什么是显卡的渲染能力呢?我们知道3D环境下最小绘制面积单位是三角面。显卡以每秒60次的频率将这些三角面投影到2D平面。而CPU同样需要以每秒60次的频率将要显示的数据准备好。并提交给显卡进行处理。 我刚巧有一台10年前的笔记本。也就是和永恒之塔同时代的笔记本。这台笔记本的渲染能力是以每秒60次的频率绘制2万个三角面。2万个三角面是什么概念呢?一个游戏角色大概要500到1千个三角面。哪么2万个三角面可以绘制40个左右的玩家。而游戏里最基本的正方形需要12个三角面。如果使用这台笔记本玩万人同屏的游戏。哪么你只能看1万个三角形在蓝色背景下奔跑。或者看见1666个正方形在蓝色背景下奔跑。 而在最新版的AMD R7-4800U内置的显卡里可以每秒60次的频率绘制500到1000万个三角形。勉强可以实现1万个游戏角色在蓝色背景下狂奔。在显卡性能允许范围内万人同屏是质量和数量的选择。万人同屏相当于把显卡性能平分1万份。这样每份的质量肯定会比较差。而在10年前把显卡性能平分1万份,就只能保证1万个三角形的同屏。在10年前只有高端显卡可以在质量和数量上满足万人同屏。所以万人同屏的技术在10年前只有少数高端玩家可以体验。而随着硬件技术的发展,显卡性能的显著提升。今天就是CPU的内置显卡也能在满足一定程度的万人同屏。 既然现在的硬件条件已经有很大的改善,为什么能够做到万人同屏的游戏还哪么少呢? 这主要是3个方面的问题。 第一个原因是虽然硬件性能不断提升,玩家对画质的要求也在不断提升。在质量和数量的比较下,策划选择了游戏质量。在游戏中技术是对策划和美术的基本支持。游戏选择质量还是数量都是策划对游戏玩法的设定。无论策划做出那种选择都能够实现是公司技术实力的体现。技术给了策划更多的选择,就意味着策划有更大的舞台,能够做出更内容更丰富的游戏。 第二个原因是网络游戏服务器的“相位技术”并不普及,只被魔兽和EVE等少数厂家垄断。导致网络游戏的承载人数非常有限,大多数游戏公司的技术只能满足5百到1千人左右的水平。受到服务器技术水平的限制,导致网络游戏的客户端无法实现万人同屏。 第三个原因是单机技术水平不足。单机游戏显然并不受到服务器处理能力的限制。显卡能力也可以得到充分释放。但要满足万人同屏需要每秒钟处理60亿条以上的游戏数据。普通的游戏厂商没有这个技术实力。 网络游戏中的难点 稍后我们来详细了解第三个原因。先简单的说下第二个。网络游戏的特点就是所有数据的处理都在服务器完成。一个是为了能够同步给其他的玩家,也是为了数据的安全。整个处理过程是玩家通过键盘鼠标生成请求命令并发往服务器。服务器接到命令后处理相关数据,并生成返回消息发给玩家和相关的玩家。玩家客户端接到命令后通过3D引擎设置相关数据,并显示到屏幕上。例如玩家移动的消息。键盘控制玩家角色向前移动,这个消息发送给服务器后,服务器记录移动数据,并将数据转发给周围的玩家。这样周围的玩家才能看这个玩家在移动。所以网络游戏中客户端功能被分为了三大部分。第一接收键盘鼠标的输入。第二网络发送并接收服务器数据。第三根据返回数据调用相应的资源并显示在屏幕。哪么能否万人同屏就受到两个条件的制约。第一个是显卡能否按游戏要求的品质显示出足够数量的对象。第二个服务器能否支持足够多的玩家在线。 我们通过前面对渲染的介绍可以知道。显卡降低游戏品质哪怕是只显示1万个三角形。也是可以实现万人同屏的。所以今天的游戏引擎和显卡性能都不是制约网络游戏中万人同屏技术的关键。只要游戏服务器能够支撑足够多的玩家就可以实现客户端的万人同屏。在上一篇文章中,我介绍了游戏服务器《使用redis实现5万人同服的“相位技术”》的文章。有兴趣的同学可以去了解下。 在单机中的难点 下面我要重点介绍单机3D游戏如何实现万人同屏。下面默认的语言环境是使用go语言。包括go语言中消息队列和服务的概念,不熟悉的同学也不用着急,下一篇文章中我会来解读示例代码。 前面我介绍了渲染并不是制约万人同屏的关键。在单机环境下制约万人同屏技术的是对游戏数据处理的能力。顾名思义万人同屏是指1万个游戏角色在屏幕中移动。如果仅仅是移动非常的容易我写了示例test_move给同学们参考。 技术困难的是在移动的过程中要不断处理各种逻辑。例如攻击附近的对象,跟随的对象,技能的触发,任务的触发,物品的拾取,攻击伤害,血量的扣减等等。这就要求游戏角色能够感知周围的其他游戏角色。显然万人同屏的另一个意义就是这1万个游戏角色要拥挤在很小的地图空间。又要感知周围游戏角色的状态进行逻辑判断。极端情况下就意味着每帧,也就是每秒60次对周围1万个角色的状态进行过滤。哪么在极端情况下,意味着1万个角色以每秒60次的频率对其他1万个角色状态进行过滤。也就是每秒钟要进行60亿次的数据筛选。假设我们所有数据处理都是在map类型中完成了。对map类型进行10万次插入需要0.016秒。每秒钟可以处理625万次。map类型读取的性能稍好可以处理1百万需要0.078秒。每秒钟可以处理1282万次。 我们的需求是每秒钟提交60次角色当前位置,并试图获取周围角色的位置用于逻辑分析。因为游戏角色被分配到不同的平行空间,也就是不同的线程。然后从不同的线程中获取当前角色周围玩家数据用于逻辑分析。这与我们在服务中使用的相位技术是一样的。哪么通过下面公式就可以得到每个角色在给定条件下能够处理的数据量为。 每个角色能够处理的数据量=(cpu的核数*每秒每线程读取能力)/(总角色数量*帧数) 假设在极端情况下,要每个角色要处理1万个其他角色的数据。例如对同屏所有人的范围伤害,被所有角色同时触发。哪么所需要的cpu核数为。 也就是如果想达到万人同屏的开发自由,当前cpu频率不变的情况下,需要有468核。这个硬件可以满足万人的现代战争的射击游戏。当然这个硬件目前还不存在。在这个公式里面除了每秒每线程的读写能力无法改变,因为取决于cpu的主频。其他的参数我们都可以适当的调整。例如保持60帧的前提下我们的射击类游戏可以做到多少角色混战呢?哪就假设总角色数量和每个角色处理的数据量相同。cpu为当前最高的128个。帧数为60帧。则计算如下。 也就是枪战类的万人同屏目前的硬件还不能满足需求。但5千人左右的同屏还是可以满足的。如果我们降低精度要求小于60帧,也可以进一步提高游戏逻辑的处理能力。 如果我们时光倒退到10年前,为什么现在有骑马砍杀类的万人同屏游戏,10年前没有这类游戏呢?因为10年前的渲染能力不够。CPU的计算能力也不够。我们计算4核的处理器的逻辑处理能力如下。 其实4核处理器的理论处理能力应该在7161个左右。因为2d策略类游戏要求并不高,可以把帧数设定为1。但10年前客户端的并行处理能力也非常的差。钢铁雄心在这类游戏算是佼佼者,单核处理能力的极限也就是1千个单位的同屏幕混战。当然P社的技术能力肯定不是最强的。对几万个角色进行军事推演的价值不言而喻,这里就不做过多的展开了。 这里我们通过锚定map类型的读写能力,将CPU的处理能力进行了量化。并将这种量化的CPU分配到1万个游戏角色上。每个角色能够分配到的CPU算力显然非常的有限。在有限的算力下又需要满足各种逻辑的处理。还要尽最大可能降低延迟到60帧,避免影响用户的体验。 在上述公式里我们忽略了角色的写入需求。因为相对于读取需求写入需求极少。假设每帧每个用户需要写入一个数据,哪么1万个用户60帧需要写入数据为。 总用户数量*帧数*写入需求=1万*60*1=60万/秒 相比于map写入能力625万/秒,写入需求可以忽略不计。在实际计算中可以对原有公式进行修正创建联立方程。分别得到写入上限和读取上限。然后反推计算,cpu核数的需求或者每秒的读写能力的需求或对帧数的需求。 (角色读取上限)=(cpu的核数*(每秒每线程读取能力))/(总角色数量*帧数) (角色写入上限)=(cpu的核数*(每秒每线程写入能力))/(总角色数量*帧数) 单机的挑战就在于CPU的核数是无法改变的,又很难像服务器一样通过分布式进行扩展。要充分利用硬件资源的前提,是首先要搞清楚需要多少硬件资源。设计软件的目地,就是充分利用硬件资源满足软件需求。搞不清自己的软件需要多少硬件资源,这样会让软件设计陷入迷茫。在这个小结中我们通过计算得到万人同屏所需要的硬件条件。和软件频率的需求,将并行开发进行了量化计算。和所有工程学一样,计算工程的上限是性能设计的前提。尤其在并行开发中,并行开发的本质就是均衡分配硬件资源。 到这里我将万人同屏的问题拆解为三个问题。并给出了每种问题的解决方向。 1) 渲染问题,和显卡硬件挂钩显卡性能不提升无法解决,网游和单机都会受到渲染问题的影响。单位时间绘制的三角面数决定了显卡的渲染能力。 2) 网游问题,主要瓶颈在服务器的万人同步。 3) 单机问题,主要瓶颈在于角色逻辑刷新的数量和频率以及硬件的限制。1万个人每秒刷60次,每次刷1万条就是60亿次数据处理。 在下一篇中我将通过示例代码,一步一步讲解如何解决单机开发中万人同屏问题。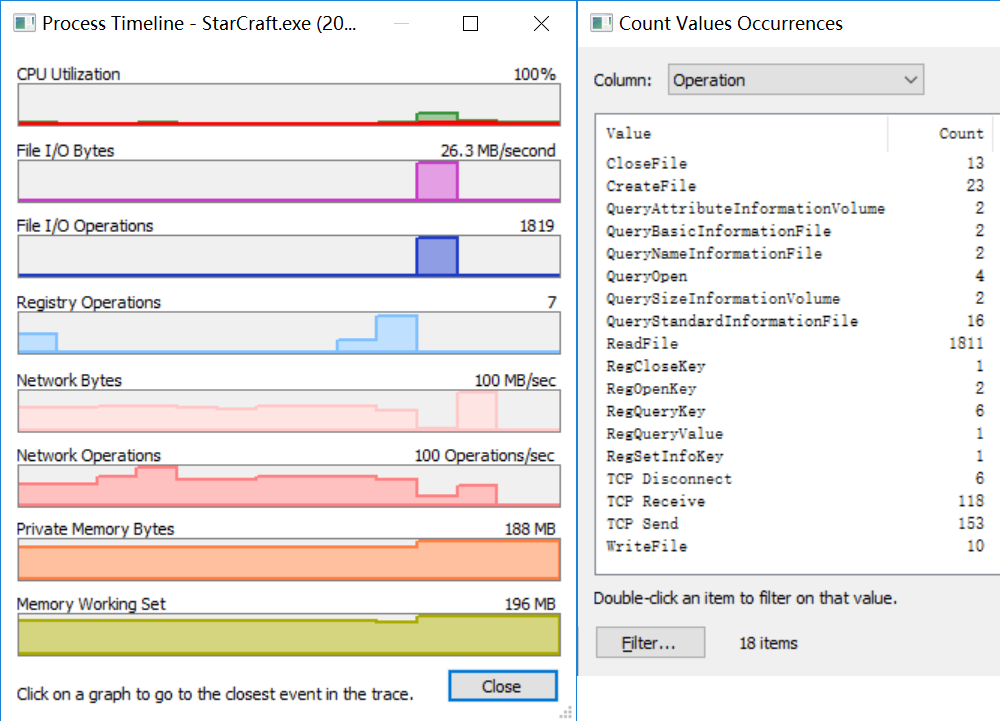


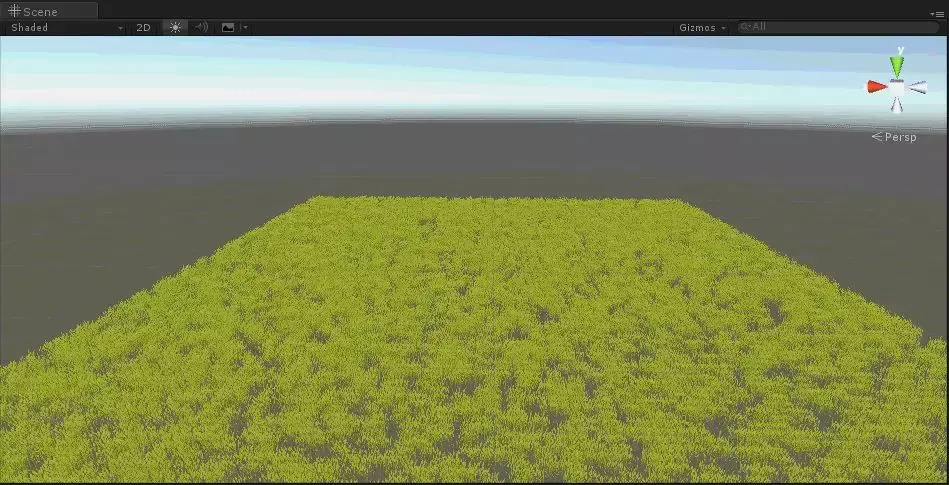
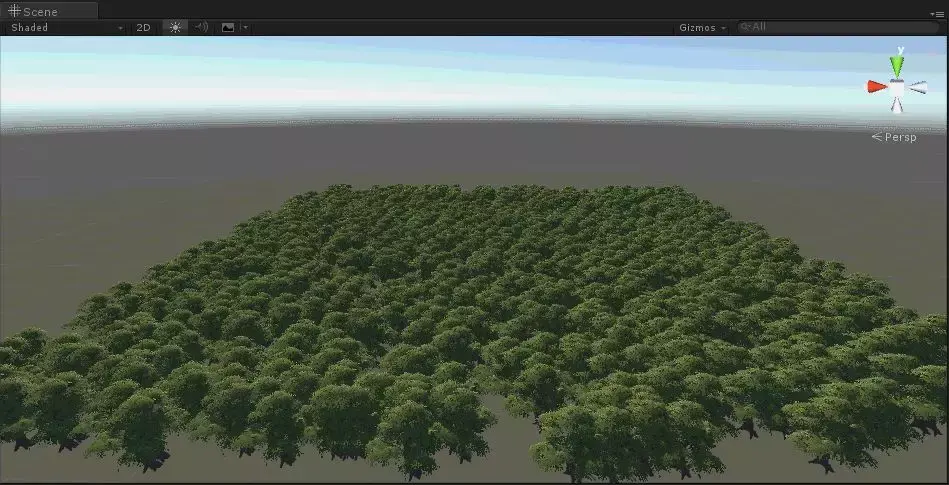
Create->Shader->StandardSurfaceShader(Instanced)SubShader{
Tags{ "RenderType"="Opaque" }
LOD 200
CGPROGRAM
// Physically based Standard lighting model, and enable shadows on all light types
// And generate the shadow pass with instancing support
#pragma surface surf Standard fullforwardshadows addshadow
// Use shader model 3.0 target, to get nicer looking lighting
#pragma target 3.0
// Enable instancing for this shader
#pragma multi_compile_instancing
// Config maxcount. See manual page.
// #pragma instancing_options
sampler2D _MainTex;
struct Input{
float2 uv_MainTex;
};
half _Glossiness;
half _Metallic;
// Declare instanced properties inside a cbuffer.
// Each instanced property is an array of by default 500(D3D)/128(GL) elements. Since D3D and GL imposes a certain limitation
// of 64KB and 16KB respectively on the size of a cubffer, the default array size thus allows two matrix arrays in one cbuffer.
// Use maxcount option on #pragma instancing_options directive to specify array size other than default (divided by 4 when used
// for GL).
UNITY_INSTANCING_CBUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(fixed4, _Color) // Make _Color an instanced property (i.e. an array)
UNITY_INSTANCING_CBUFFER_END
void surf (Input IN, inout SurfaceOutputStandard o){
// Albedo comes from a texture tinted by color
fixed4 c=tex2D (_MainTex, IN.uv_MainTex) * UNITY_ACCESS_INSTANCED_PROP(_Color);
o.Albedo=c.rgb;
// Metallic and smoothness come from slider variables
o.Metallic=_Metallic;
o.Smoothness=_Glossiness;
o.Alpha=c.a;
}
ENDCG
}Shader "SimplestInstancedShader"
{
Properties
{
_Color ("Color", Color)=(1, 1, 1, 1)
}
SubShader
{
Tags{ "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct v2f
{
float4 vertex : SV_POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID // necessary only if you want to access instanced properties in fragment Shader.
};
UNITY_INSTANCING_CBUFFER_START(MyProperties)
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_INSTANCING_CBUFFER_END
v2f vert(appdata v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v);
UNITY_TRANSFER_INSTANCE_ID(v, o); // necessary only if you want to access instanced properties in the fragment Shader.
o.vertex=UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag(v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i); // necessary only if any instanced properties are going to be accessed in the fragment Shader.
return UNITY_ACCESS_INSTANCED_PROP(_Color);
}
ENDCG
}
}
}
每个Instance独有的属性必须定义在一个遵循特殊命名规则的Constant Buffer中。使用这对宏来定义这些Constant Buffer。“name”参数可以是任意字符串。
定义一个具有特定类型和名字的每个Instance独有的Shader属性。这个宏实际会定义一个Uniform数组。
这个宏必须在Vertex Shader的最开始调用,如果你需要在Fragment Shader里访问Instanced属性,则需要在Fragment Shader的开始也用一下。这个宏的目的在于让Instance ID在Shader函数里也能够被访问到。
在Vertex Shader中把Instance ID从输入结构拷贝至输出结构中。只有当你需要在Fragment Shader中访问每个Instance独有的属性时才需要写这个宏。
访问每个Instance独有的属性。这个宏会使用Instance ID作为索引到Uniform数组中去取当前Instance对应的数据。(这个宏在上面的shader中没有出现,在下面我自定义的shader中有引用到)。#pragma multi_compile_instancing#pragma multi_compile LIGHTMAP_OFF LIGHTMAP_ON //开关编译选项
struct v2f
{
float4 pos : SV_POSITION;
float3 lightDir : TEXCOORD0;
float3 normal : TEXCOORD1;
float2 uv : TEXCOORD2;
LIGHTING_COORDS(3, 4)
#ifdef LIGHTMAP_ON
flost2 uv_LightMap : TEXCOORD5;
#endif
UNITY_VERTEX_INPUT_INSTANCE_ID
}#ifdef LIGHTMAP_ON
o.uv_LightMap=v.texcoord1.xy * _LightMap_ST.xy + _LightMap_ST.zw;
#endif#ifdef LIGHTMAP_ON
fixed3 lm=DecodeLightmap(UNITY_SAMPLE_TEX2D(_LightMap, i.uv_LightMap.xy));
finalColor.rgb *=lm;
#endifTags{ "LightMode"="ForwardBase" }#ifdef LIGHTMAP_ON
o.uv_LightMap=v.texcoord1.xy * _LightMap_ST.xy + _LightMap_ST.zw;
#endifLIGHTING_COORDS(3, 4)pass
{
Tags{ "LightMode"="ForwardBase" }
CGPROGRAM
#pragma target 3.0
#pragma fragmentoption
ARB_precision_hint_fastest
#pragma vertex vertShadow
#pragma fragment fragShadow
#pragma multi_compile_fwdbase
#pragma multi_compile_instancing
#include "UnityCG.cginc"
#include "AutoLight.cginc"
#pragma multi_compile LIGHTMAP_OFF LIGHTMAP_ON //开关编译选项
sampler2D _DiffuseTexture;
float4 _DiffuseTint;
float4 _LightColor0;
sampler2D _LightMap;//传进来的lightmap
float4 _LightMap_ST;//
struct v2f
{
float4 pos : SV_POSITION;
float3 lightDir : TEXCOORD0;
float3 normal : TEXCOORD1;
float2 uv : TEXCOORD2;
LIGHTING_COORDS(3, 4)
#ifdef LIGHTMAP_ON
flost2 uv_LightMap : TEXCOORD5;
#endif
UNITY_VERTEX_INPUT_INSTANCE_ID
};
UNITY_INSTANCING_CBUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(fixed4, _Color) // Make _Color an instanced property (i.e. an array)
UNITY_INSTANCING_CBUFFER_END
v2f vertShadow(appdata_base v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v);
UNITY_TRANSFER_INSTANCE_ID(v, o);
o.pos=mul(UNITY_MATRIX_MVP, v.vertex);
o.uv=v.texcoord;
o.lightDir=normalize(ObjSpaceLightDir(v.vertex));
o.normal=normalize(v.normal).xyz;
#ifdef LIGHTMAP_ON
//o.uv_LightMap=v.texcoord1.xy * unity_LightmapST.xy + unity_LightmapST.zw;
o.uv_LightMap=v.texcoord1.xy * _LightMap_ST.xy + _LightMap_ST.zw;
#endif
TRANSFER_VERTEX_TO_FRAGMENT(o);
return o;
}
float4 fragShadow(v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
float3 L=normalize(i.lightDir);
float3 N=normalize(i.normal);
float attenuation=LIGHT_ATTENUATION(i) * 2;
float4 ambient=UNITY_LIGHTMODEL_AMBIENT * 2;
float NdotL=saturate(dot(N, L));
float4 diffuseTerm=NdotL * _LightColor0 * _DiffuseTint * attenuation;
float4 diffuse=tex2D(_DiffuseTexture, i.uv)*UNITY_ACCESS_INSTANCED_PROP(_Color);//这里用宏访问Instance的颜色属性
float4 finalColor=(ambient + diffuseTerm) * diffuse;
#ifdef LIGHTMAP_ON
//fixed3 lm=DecodeLightmap(UNITY_SAMPLE_TEX2D(unity_Lightmap, i.uv_LightMap.xy));
fixed3 lm=DecodeLightmap(UNITY_SAMPLE_TEX2D(_LightMap, i.uv_LightMap.xy));
finalColor.rgb *=lm;
#endif
return finalColor;
}
ENDCG
}/*阴影投射需要自定义,否则不支持GPU Instance同时需要包括指令multi_compile_instancing以及
在vert及frag函数中取instance id否则多个对象将得不到阴影投射
*/
Pass{
Tags{ "LightMode"="ShadowCaster" }
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_shadowcaster
#pragma multi_compile_instancing
#include "UnityCG.cginc"
sampler2D _Shadow;
struct v2f{
V2F_SHADOW_CASTER;
float2 uv:TEXCOORD2;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
v2f vert(appdata_base v)
{
v2f o;
UNITY_SETUP_INSTANCE_ID(v);
UNITY_TRANSFER_INSTANCE_ID(v, o);//
o.uv=v.texcoord.xy;
TRANSFER_SHADOW_CASTER_NORMALOFFSET(o);
return o;
}
float4 frag(v2f i) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(i);
fixed alpha=tex2D(_Shadow, i.uv).a;
clip(alpha - 0.5);
SHADOW_CASTER_FRAGMENT(i)
}
ENDCG
}bool IsCanCulling(Transform tran)
{
//必要时候,摄像机的视域体的计算 放置在裁剪判断之外,避免多次坐标变换开销,保证每帧只有一次
Vector3 viewVec=Camera.main.WorldToViewportPoint(tran.position);
var far=Camera.main.farClipPlane ;
var near=Camera.main.nearClipPlane;
if (viewVec.x > 0 && viewVec.x < 1 && viewVec.y > 0 && viewVec.y < 1 && viewVec.z > near && viewVec.z < far)
return false;
else
return true;
}public class testInstance : MonoBehaviour
{
//草材质用到的mesh
Mesh mesh;
Material mat;
public GameObject m_prefab;
Matrix4x4[]matrix;
ShadowCastingMode castShadows;//阴影选项
public int InstanceCount=10;
//树的预制体由树干和树叶两个mesh组成
MeshFilter[]meshFs;
Renderer[]renders;
//这个变量类似于unity5.6材质属性的Enable Instance Variants勾选项
public bool turnOnInstance=true;
void Start()
{
if (m_prefab==null)
return;
Shader.EnableKeyword("LIGHTMAP_ON");//开启lightmap
//Shader.DisableKeyword("LIGHTMAP_OFF");
var mf=m_prefab.GetComponent<MeshFilter>();
if (mf)
{
mesh=m_prefab.GetComponent<MeshFilter>().sharedMesh;
mat=m_prefab.GetComponent<Renderer>().sharedMaterial;
}
//如果一个预制体 由多个mesh组成,则需要绘制多少次
if(mesh==null)
{
meshFs=m_prefab.GetComponentsInChildren<MeshFilter>();
}
if(mat==null)
{
renders=m_prefab.GetComponentsInChildren<Renderer>();
}
matrix=new Matrix4x4[InstanceCount];
castShadows=ShadowCastingMode.On;
//随机生成位置与缩放
for (int i=0; i < InstanceCount; i++)
{
/// random position
float x=Random.Range(-50, 50);
float y=Random.Range(-3, 3);
float z=Random.Range(-50, 50);
matrix[i]=Matrix4x4.identity; /// set default identity
//设置位置
matrix[i].SetColumn(3, new Vector4(x, 0.5f, z, 1)); /// 4th colummn: set position
//设置缩放
//matrix[i].m00=Mathf.Max(1, x);
//matrix[i].m11=Mathf.Max(1, y);
//matrix[i].m22=Mathf.Max(1, z);
}
}
void Update()
{
if (turnOnInstance)
{
castShadows=ShadowCastingMode.On;
if(mesh)
Graphics.DrawMeshInstanced(mesh, 0, mat, matrix, matrix.Length, props, castShadows, true, 0, null);
else
{
for(int i=0; i < meshFs.Length; ++i)
{
Graphics.DrawMeshInstanced(meshFs[i].sharedMesh, 0, renders[i].sharedMaterial, matrix, matrix.Length, props, castShadows, true, 0, null);
}
}
}
}
}


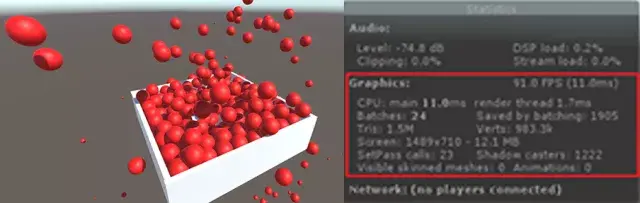
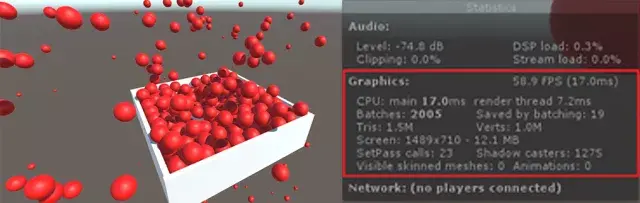
工欲善其事必先利其器,这里我们来讲解Unity3D优化所需的工具
我们通过Window——>Profiler来激活Unity Profile面板
在CPU usage profiler中的列表题分别为:
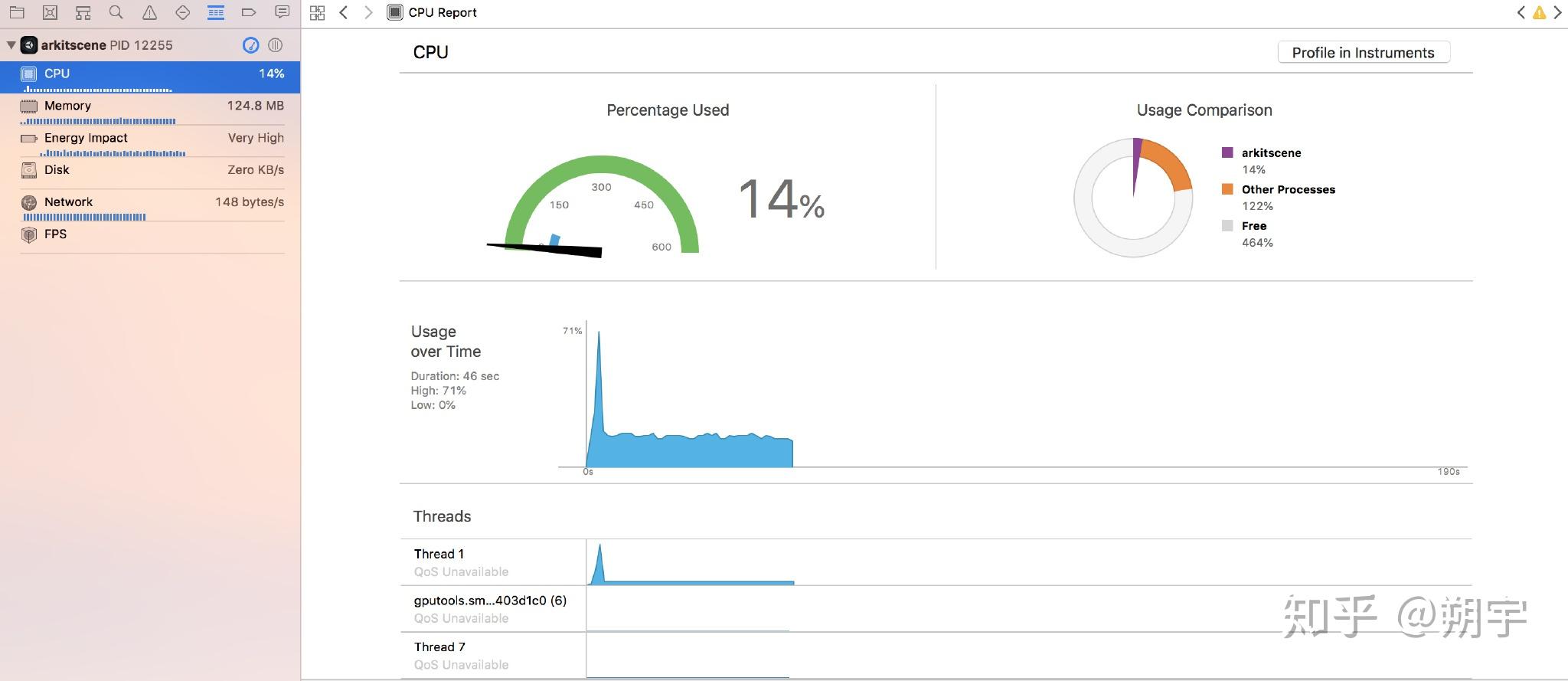
Total:当前任务的时间消耗占当前帧cpu消耗的时间比例。
Self:任务自身时间消耗占当前帧cpu消耗的时间比例。
Calls:当前任务在当前帧内被调用的次数。
GC Alloc:当前任务在当前帧内进行过内存回收和分配的次数。
Time ms:当前任务在当前帧内的耗时总时间。
Self ms:当前任务自身(不包含内部的子任务)时间消耗。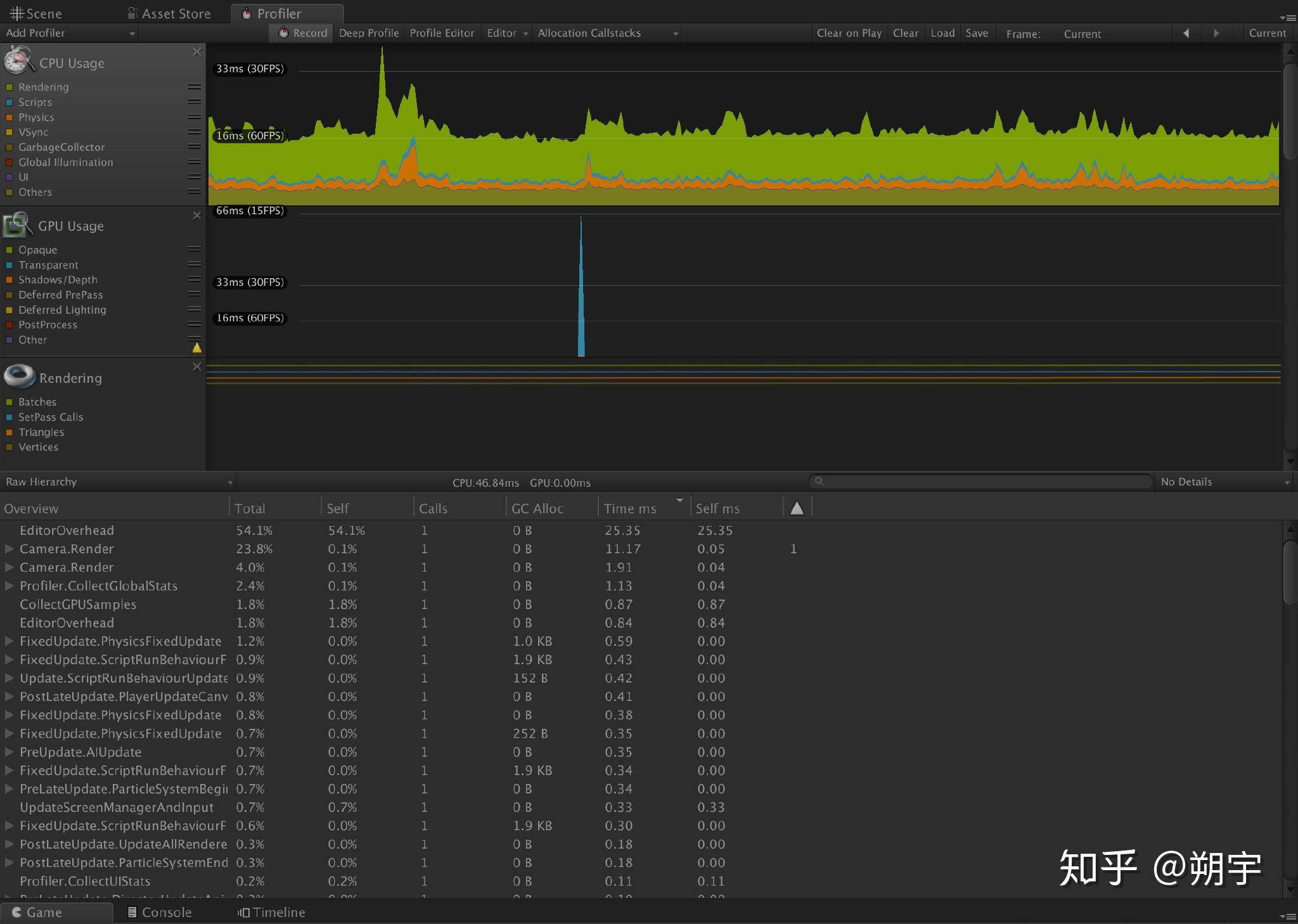
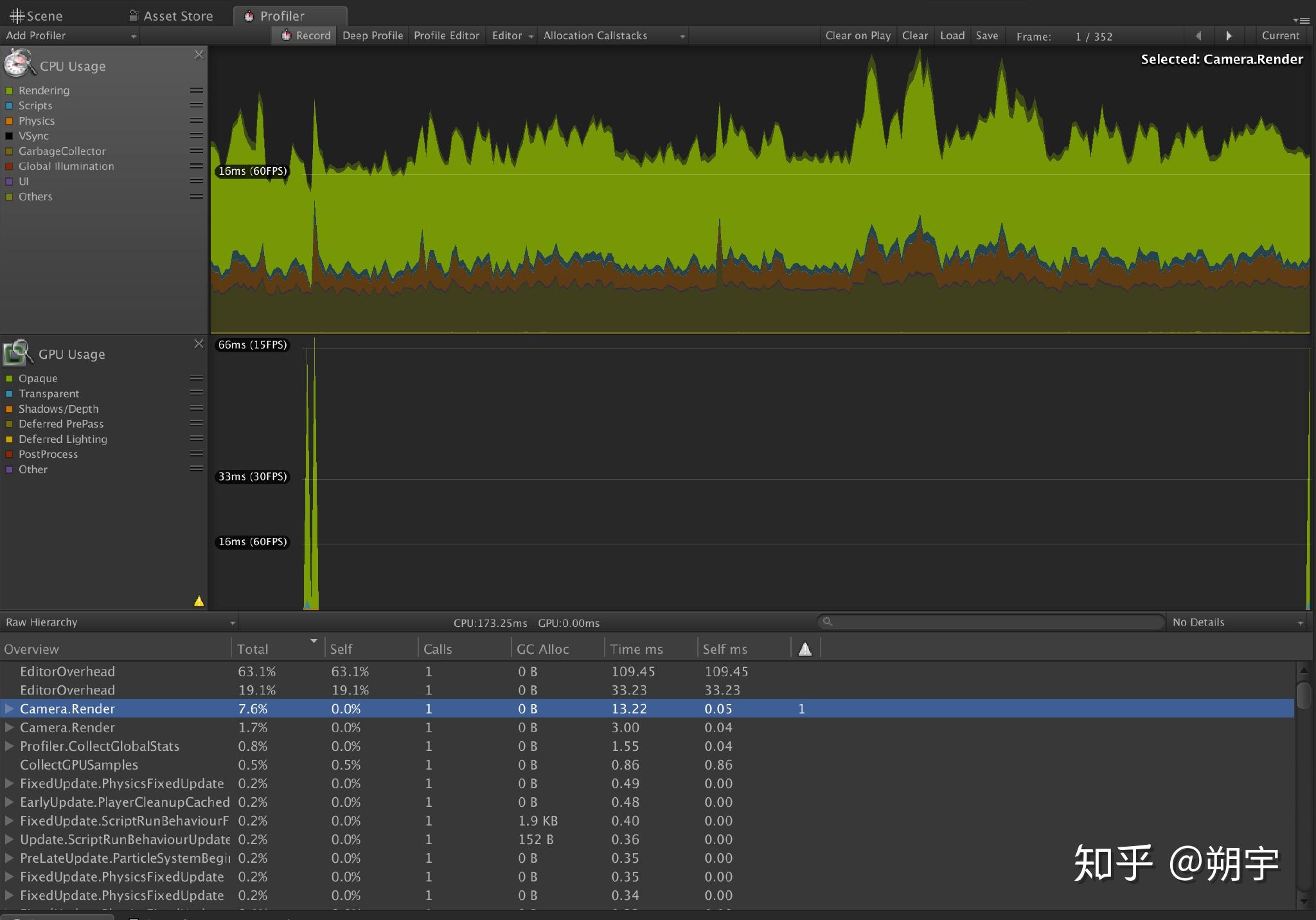
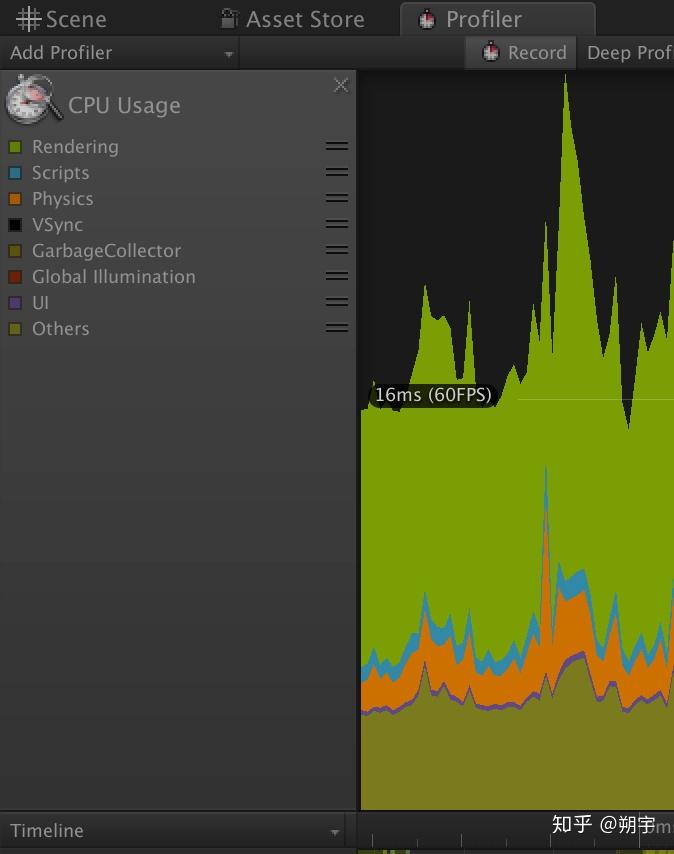
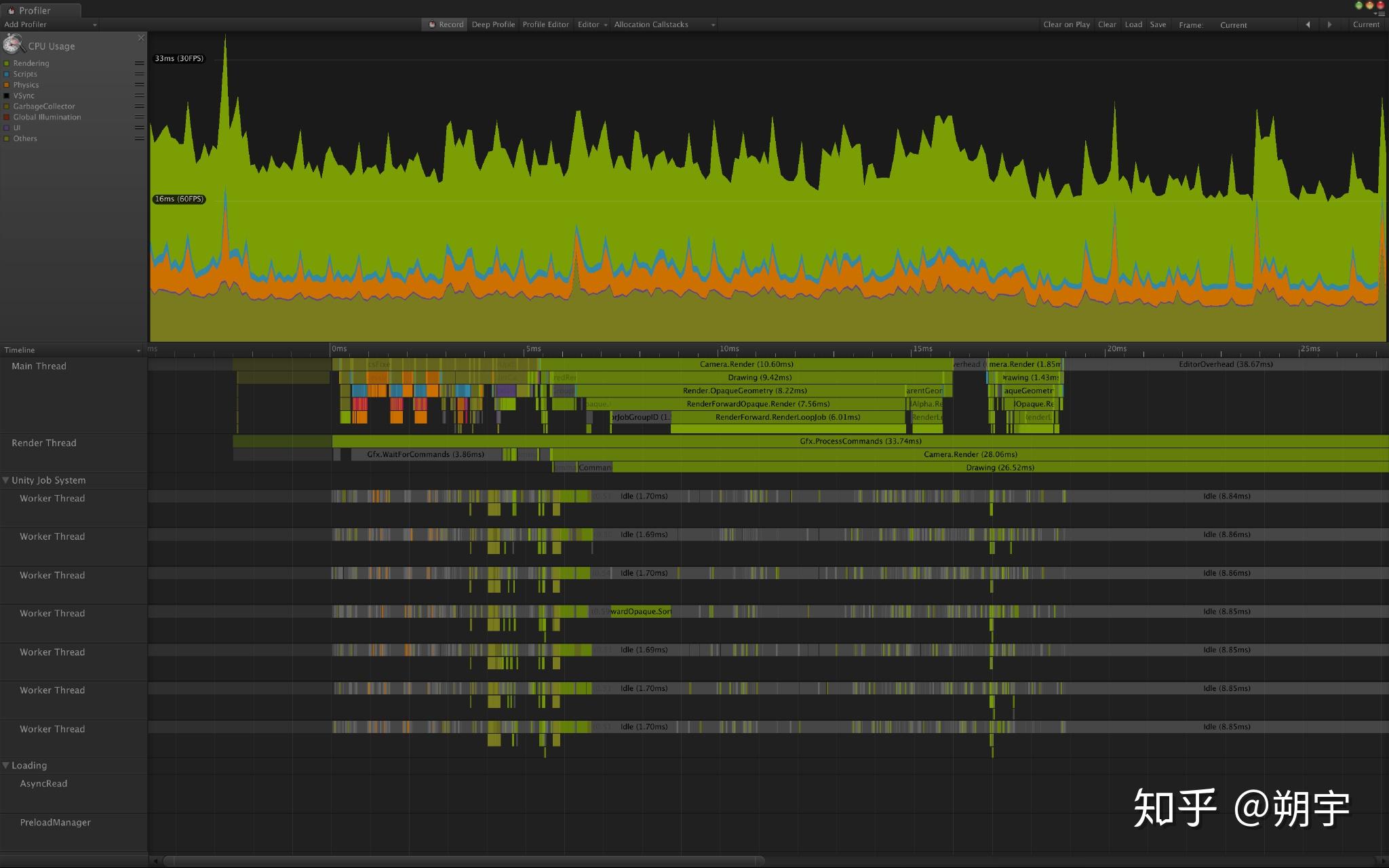
例如,当我们的游戏运行的比较慢时,我们可能一开始先查看CPU usage profiler,CPU usage profiler也是在我们进行优化分析时最常用的Profiler。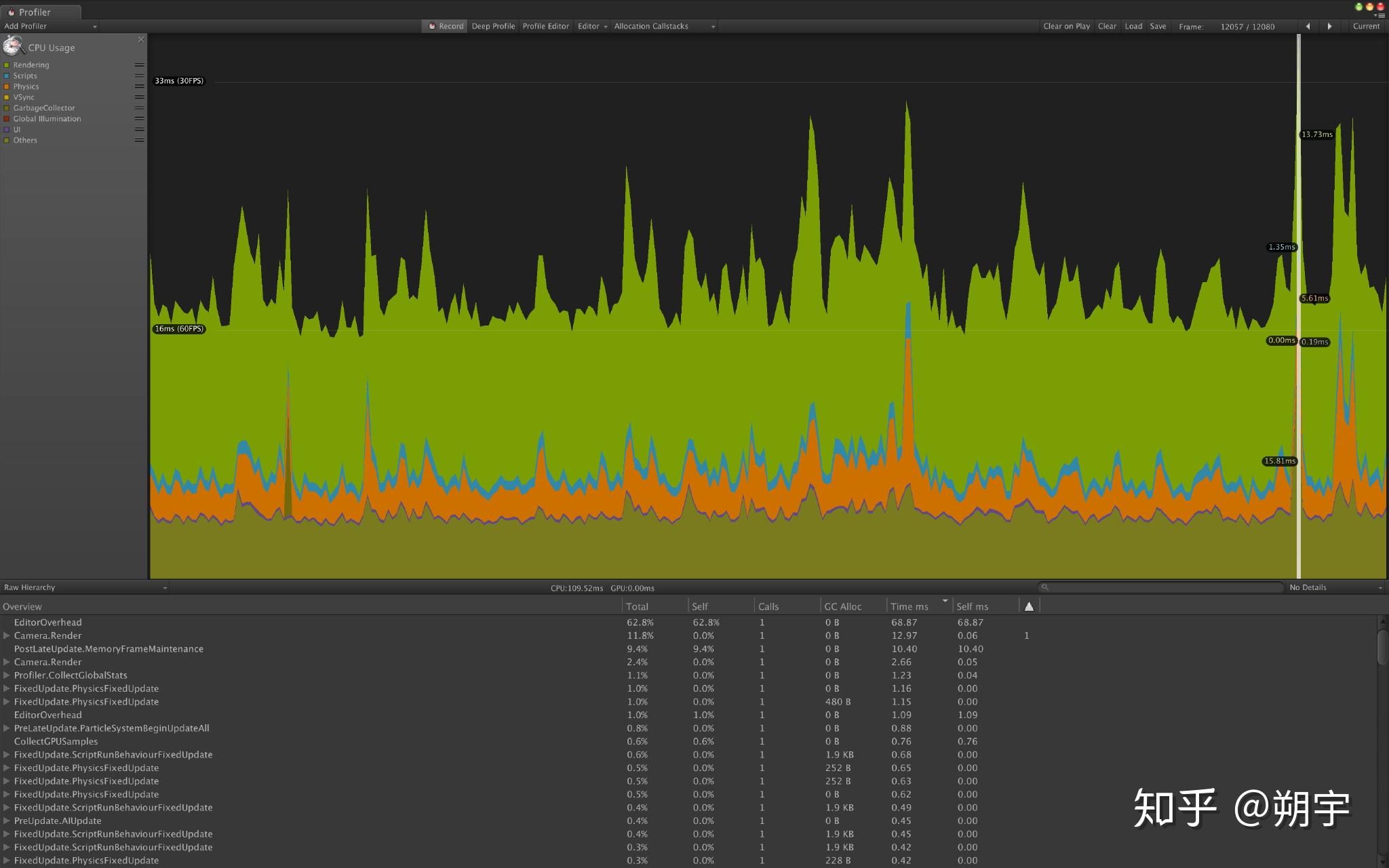
1. GC Allow: 任何一次性内存分配大于2KB的选项。
每帧都具有20B以上内存分配的选项 。GC相关的问题和优化,在之后我们会详细的介绍。
1. Texture: 检查是否有重复资源和超大内存是否需要压缩等.。
2. AnimationClip: 重点检查是否有重复资源.。
3. Mesh: 重点检查是否有重复资源。
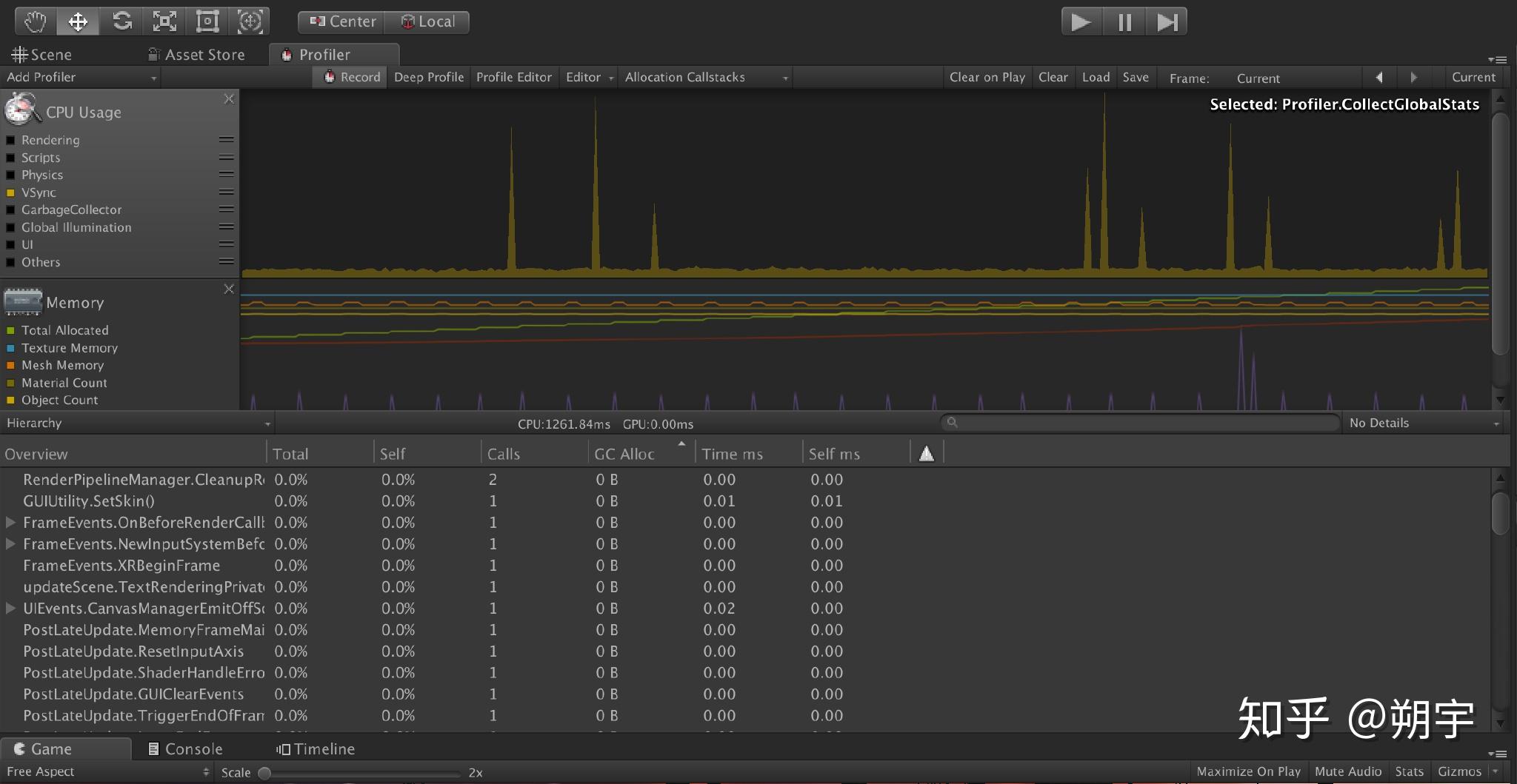
我们来简单的介绍一下什么是垂直同步,以及关闭它之后会发生什么。
要理解垂直同步,首先明白显示器的工作原理。
显示器上的所有图像都是单个像素组成了水平扫描线,水平扫描线在垂直方向的堆积形成了完整的画面,无论是隔行扫描还是逐行扫描,显示器都有两种同步参数——水平同步和垂直同步。
垂直和水平是CRT显示器中两个基本的同步信号,水平同步信号决定了CRT画出一条横越屏幕线的时间,垂直同步信号决定了CRT从屏幕顶部画到底部,再返回原始位置的时间,而垂直同步代表着CRT显示器的刷新率水准。
在游戏项目中,如果我们选择等待垂直同步信号也就是打开垂直同步,在游戏中或许性能较强的显卡会迅速的绘制完一屏的图像,但是没有垂直同步信号的到达,显卡无法绘制下一屏,只有等85单位的信号到达,才可以绘制。这样FPS自然要受到刷新率运行值的制约。
而如果我们选择不等待垂直同步信号,那么游戏中绘制完一屏画面,显卡和显示器无需等待垂直同步信号就可以开始下一屏图像的绘制,自然可以完全发挥显卡的实力。
但是,正是因为垂直同步的存在,才能使得游戏进程和显示器刷新率同步,使得画面更加平滑和稳定。取消了垂直同步信号,固然可以换来更快的速度,但是在图像的连续性上势必会打折扣。
需要注意,LCD显示器其实也是存在刷新率的,但其机制与CRT不同,这里不做过多赘述,但是垂直同步和水平同步对于LCD显示器来说,一样是有必要的。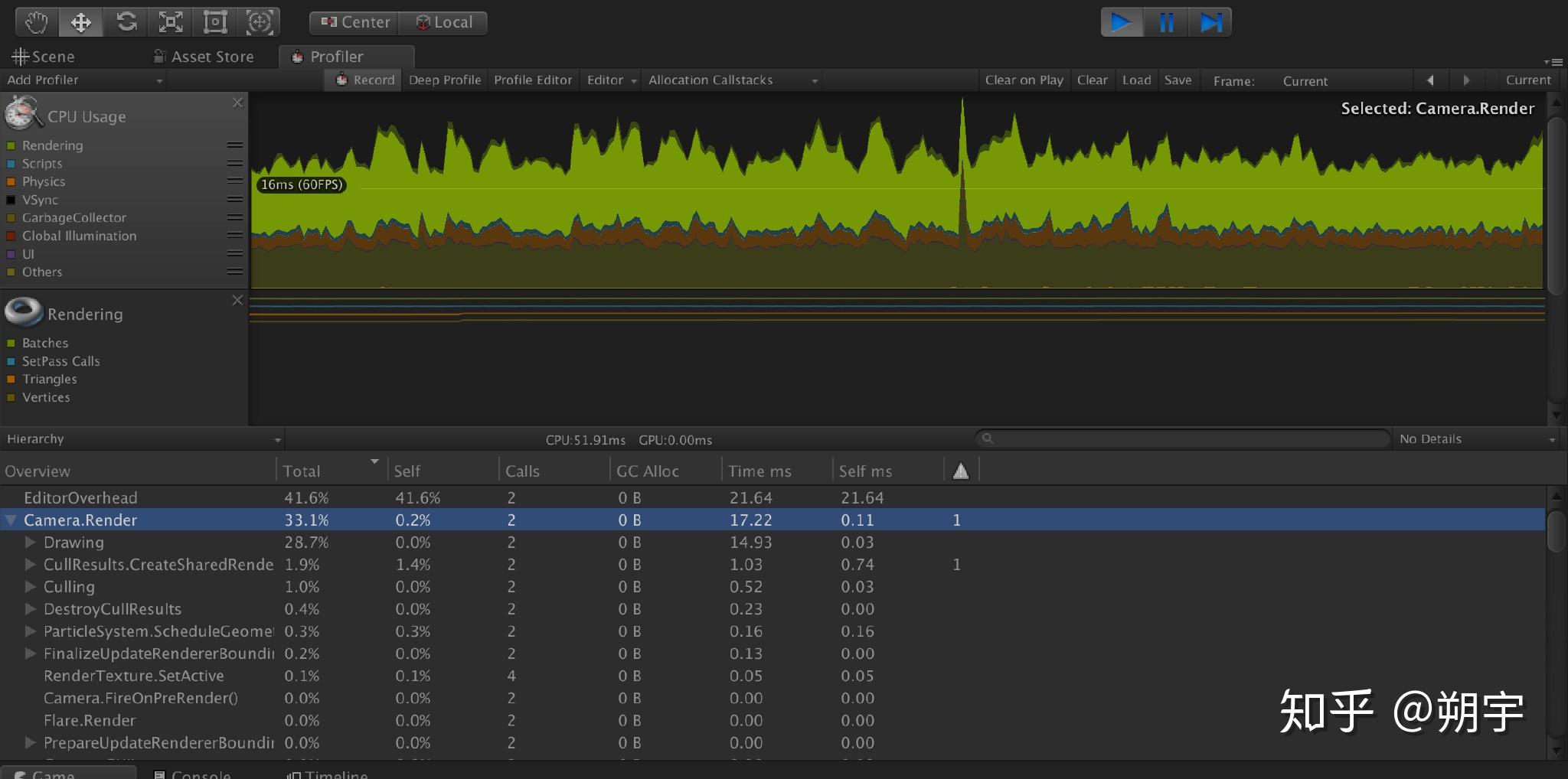
Camera Render是相机渲染工作的CPU占用量,在实际项目中,渲染是最常见的引起性能问题的原因。 而因为渲染而引起的性能问题的优化是一个非常大的工程,这方面的优化方法在我们后续的文章中会有详细的教程去学习和分析。在这里,我们只需要先了解。
我们这个项目的优化中,无疑,渲染造成的性能损耗是一个大头。
我们按照GC Alloc的顺序来显示,可以看到下图。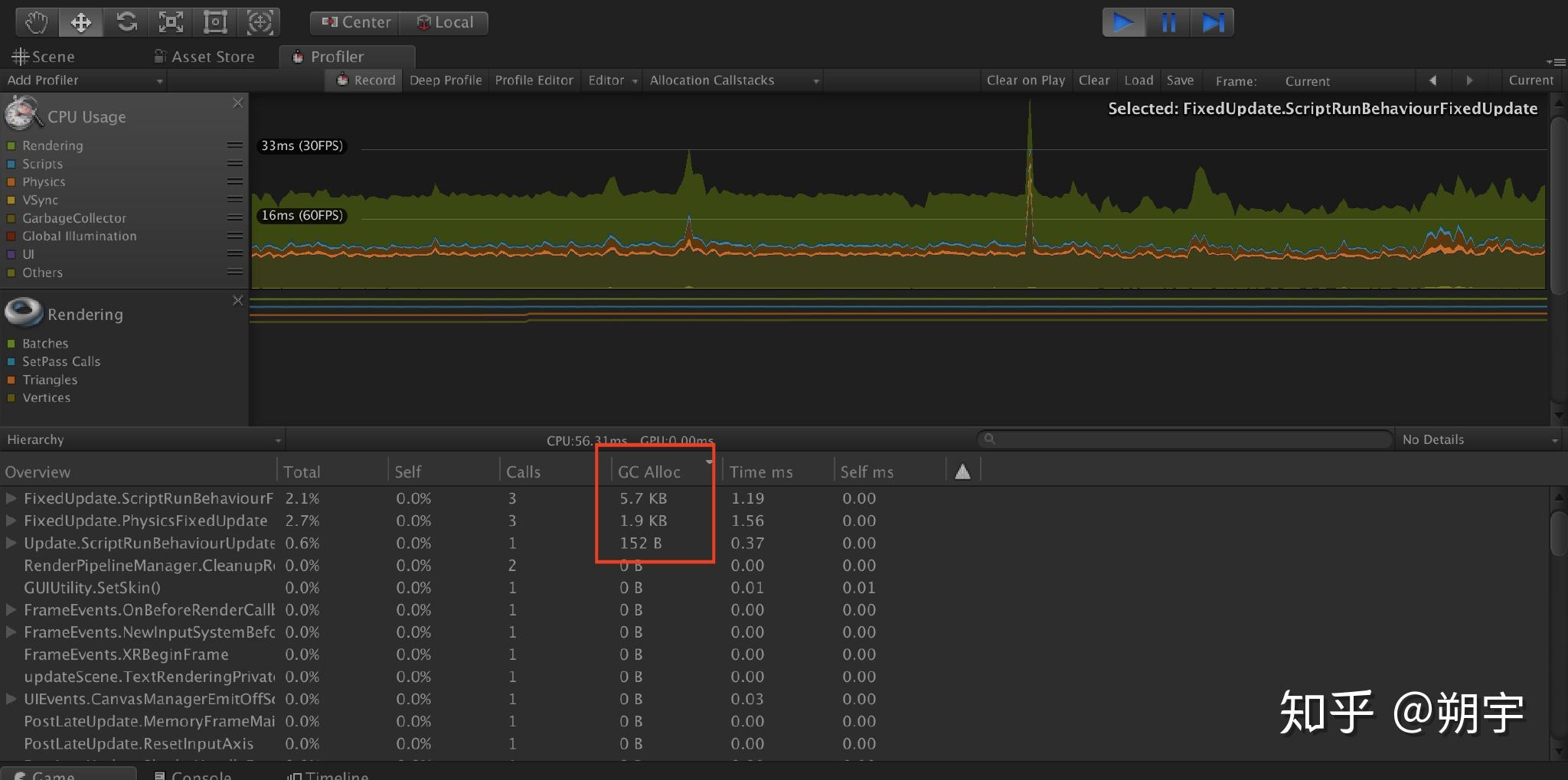
在之前我们提到过,GC Alloc中,任何一次性内存分配大于2KB的选项,每帧都具有20B以上内存分配的选项 ,是需要我们重点关注的,显而易见,我们的项目中,对于GC的优化,也有很大的问题。关于CG的问题,我们会在下一篇Unity3D性能优化——CPU篇中,详细的介绍。这里我们大致介绍一下GC的机制,要想了解垃圾回收如何工作以及何时被触发,我们首先需要了解unity的内存管理机制。Unity主要采用自动内存管理的机制,开发时在代码中不需要详细地告诉unity如何进行内存管理,unity内部自身会进行内存管理。
Unity内部有两个内存管理池,堆内存和栈内存,垃圾回收主要是指堆上的内存分配和回收,unity中会定时对堆内存进行GC操作。
当堆内存上一个变量不再处于激活状态的时候,其所占用的内存并不会立刻被回收,不再使用的内存只会在GC的时候才会被回收。
每次运行GC的时候,GC会检查堆内存上的每个存储变量,对每个变量会检测其引用是否处于激活状态,如果变量的引用不再处于激活状态,则会被标记为可回收,被标记的变量会被移除,其所占有的内存会被回收到堆内存上。
GC操作是一个极其耗费的操作,堆内存上的变量或者引用越多则其运行的操作会更多,耗费的时间越长。 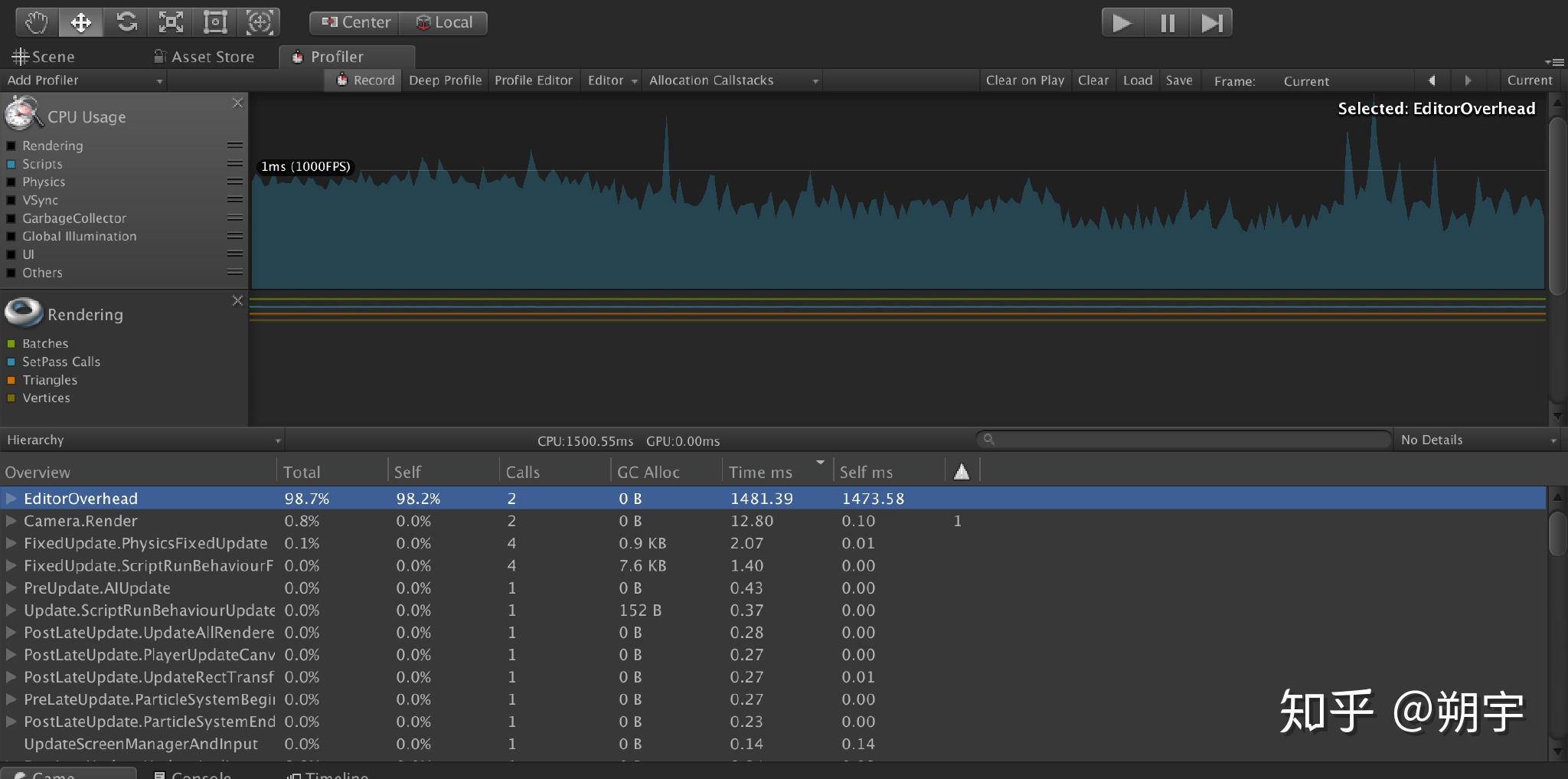
如果在一个很慢的帧中,一大部分时间被脚本运行所消耗,这意味着这些慢的脚本可能就是引起性能问题的主因。我们可以更加深入的分析数据来确认。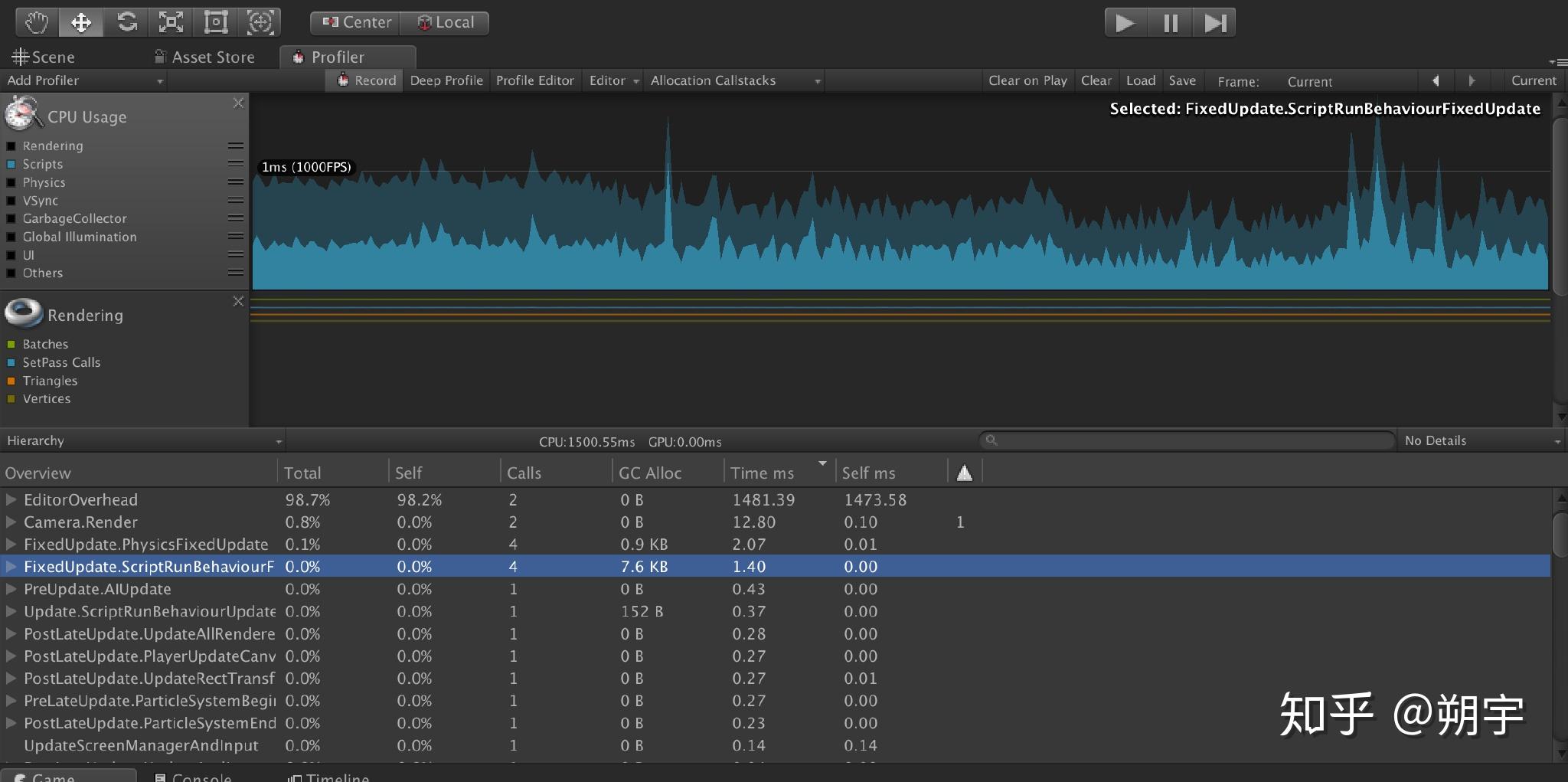
打包完成后,使用Xcode打开文件,在Xcode中选择Product ——> Scheme——> Manage Schemes
然后会出现如下界面
我们双击这个项目会出现如下界面
然后我们在左侧选中Run,然后在右侧面板选择Options
在GPU frame Capture中选择OpenGL ES或者Metal。
在Debug模式下运行项目,当项目在真机上完全加载后,就可以进入Debug Navigator(View ——> Navigators ——> Show Debug Navigator)
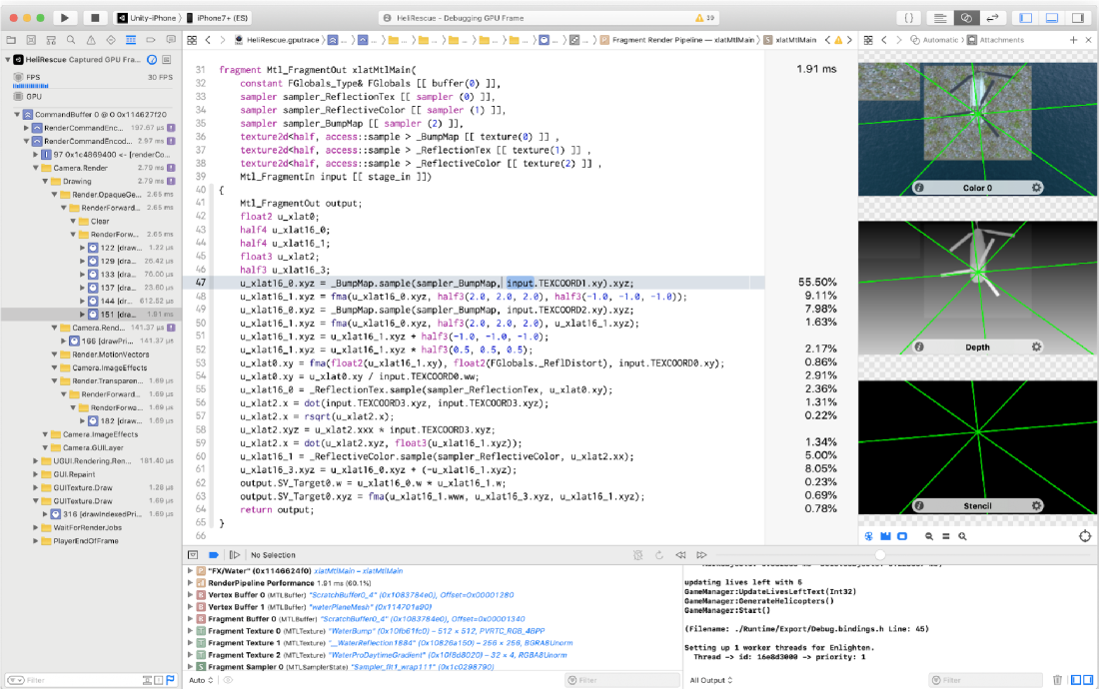
XCode的Capture GPU frame功能能高效且定量地定位到GPU中shader的消耗。
理解渲染最重要的是:为了渲染一帧,CPU和GPU必须都完成他们的任务。他们中的任何一个花费了过长的时间去完成任务,都会造成渲染延迟。渲染问题有两个基本的原因。第一类问题是由低效的渲染管线引起。当渲染管线中一步或者多步花费了太长时间,打断了平滑的数据流时,渲染管线会很低效。渲染管线的低效被称为瓶颈。第二类问题是由于,渲染管线被塞入了太多的数据。即使是最高效的渲染管线,对于一帧中可以处理的数据量也是有限制的。
渲染优化的主要目的就是减少渲染的工作量,控制渲染的工作量是保证效率的根本,而每帧渲染的顶点数量是衡量渲染工作量最直观的标准之一:
每帧可渲染的顶点数量主要取决于设备的CPU和GPU。 不过通常来说PC游戏每帧渲染的顶点个数不宜超过2M,移动游戏每帧渲染的顶点数量不宜超过0.1M。 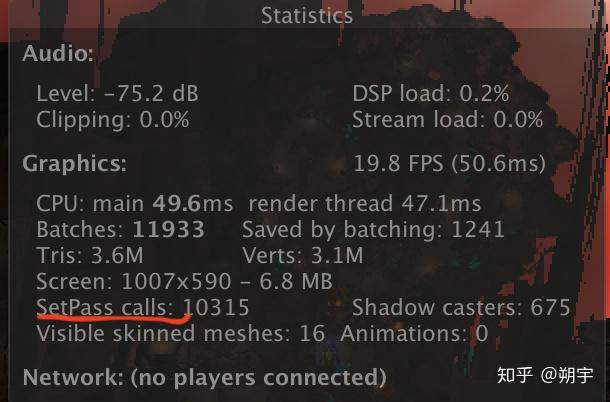
把所有物体选中,Inspector面板中的static下拉菜单中勾选Occlusion Static 和 Occludee Static。
在Window中选择Occlusion Culling。
然后在Occlusion Culling面板中选择Bake,并点击右下角Bake按钮
在bake后,我们可以对比遮挡剔除前后的差别
(遮挡剔除前)
(遮挡剔除后)
Smallest Occluder:设置最小遮挡物的尺寸,当遮挡物的长度或者宽大于设定值时,该物体才能够遮挡住后面的物体。
Smallest Hole:设置最小孔的尺寸,当穿过物体内部的孔或者多个物体堆叠形成的孔的大小小于设定的值时,遮挡剔除烘焙将忽略该孔的存在。
Backface Threshold:设置背面移除阈值,用于优化场景,当该值为100时,摄像机拍摄不到的背面信息也会完整保留;当该值较小时,系统将对背面信息进行优化甚至去掉背景信息。Occlusion Culling(遮挡剔除)是对于场景优化最重要的技术之一,对于较大的场景一定要使用遮挡剔除,大场景中过多的绘制渲染会造成很大的性能损耗。
为了降低性能损耗同时保证游戏质量,Far的值应该合理控制,不要造成不好的游戏体验,或者我们可以用雾来掩盖不被渲染的远端。
1.Lightmap(光照贴图)
为了了解光照贴图,我们先新建一个项目
我们有五个点光源,在运行的时候可以看到Setpass Calls比较大。而我们的目的就是减少Setpass Calls。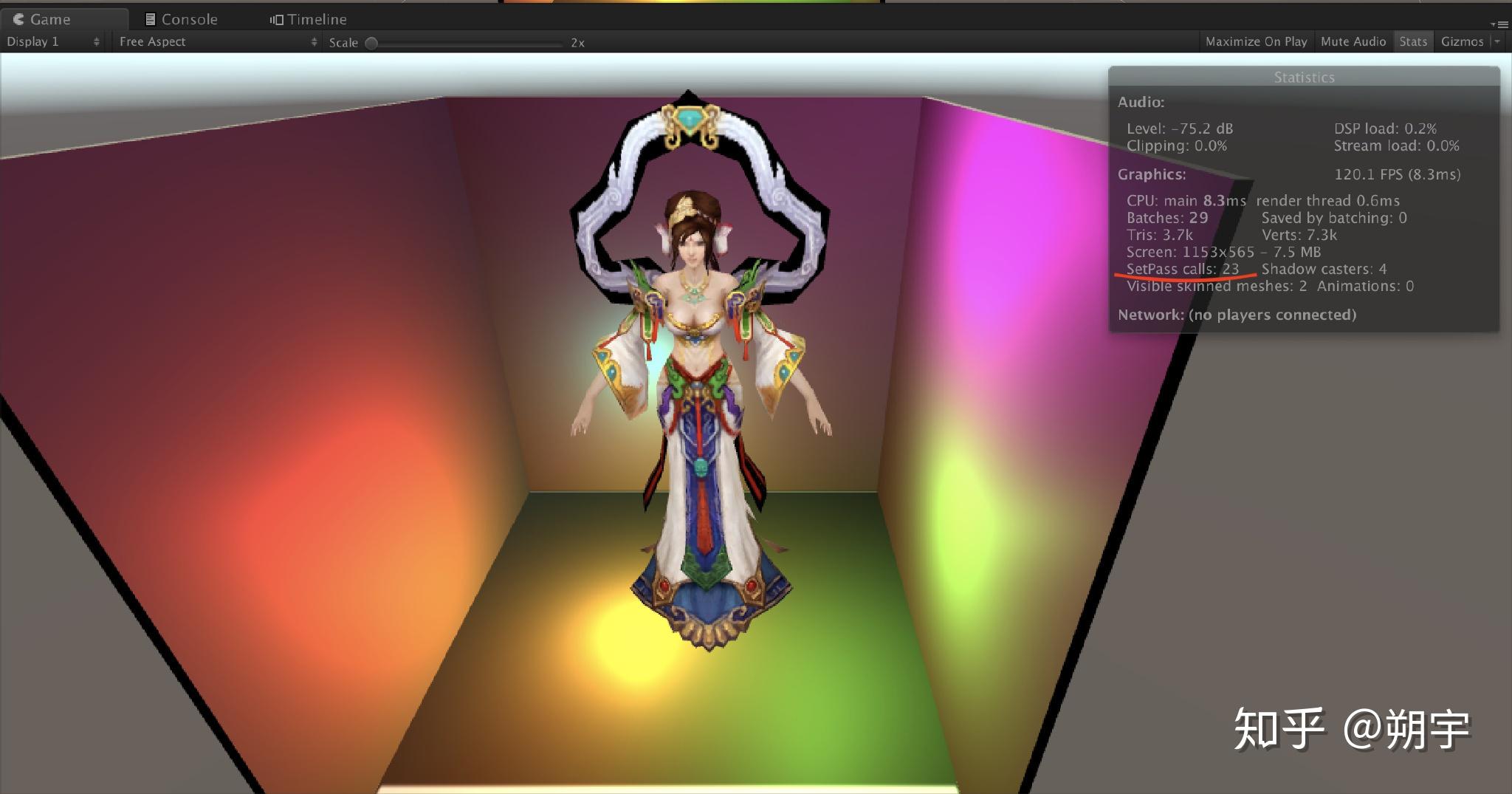
首先我们把被光照到的物体勾选上Lightmap Static。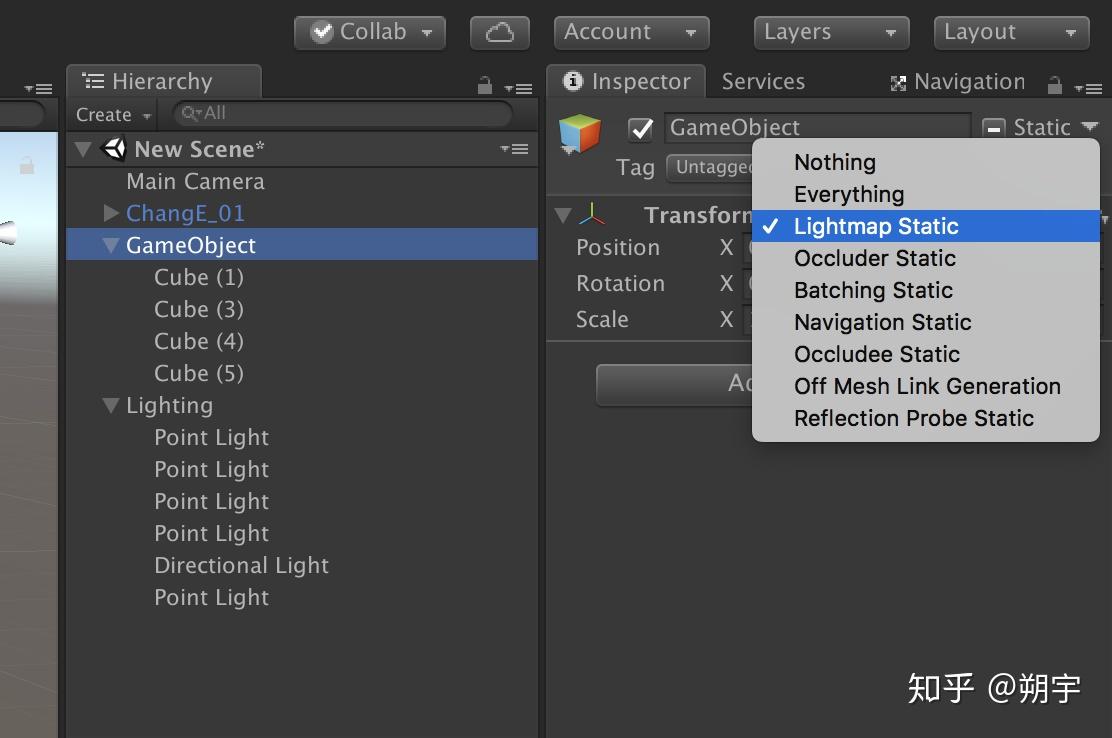
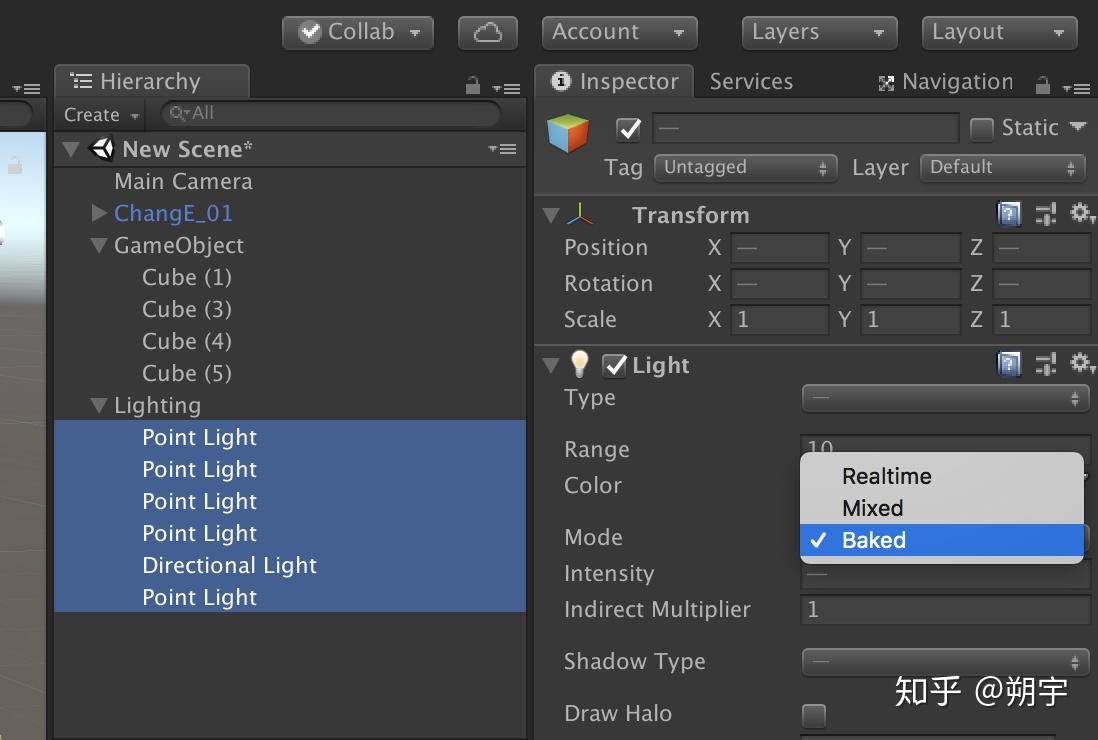
然后把所有光源的Mode设置为BakedRealtime: 实时(默认)/ Baked: 烘焙 / Mixed: 混合
选择window ——> Lighting ——> Settings
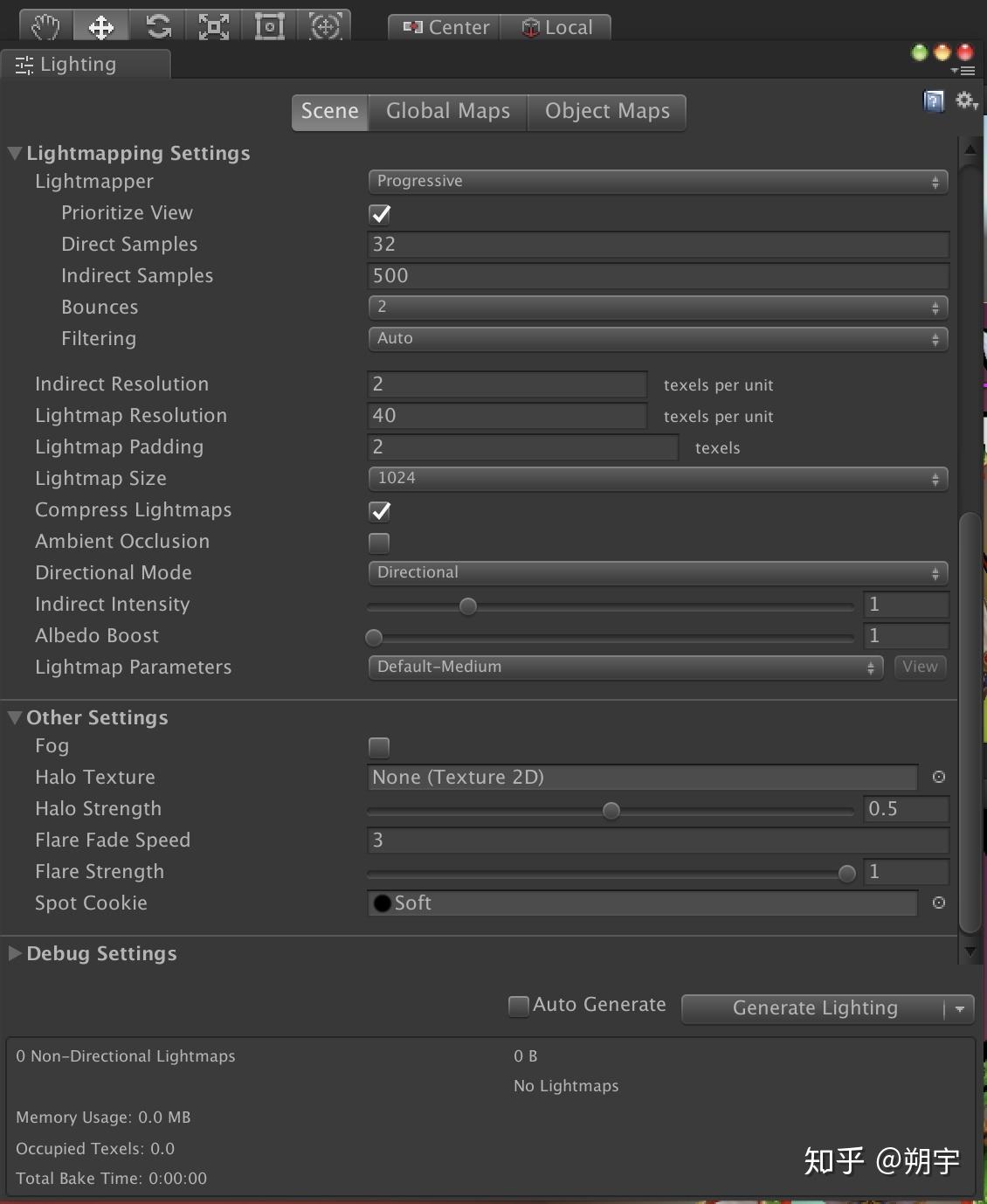
我们在Lighting设置面板中可以进行一些Lightmapping设置,这里我们点击右下角的Generate Lighting,也可以勾选旁边的Auto Genenrate(不建议勾选)然后开始生成光照贴图,完成后会出现以下文件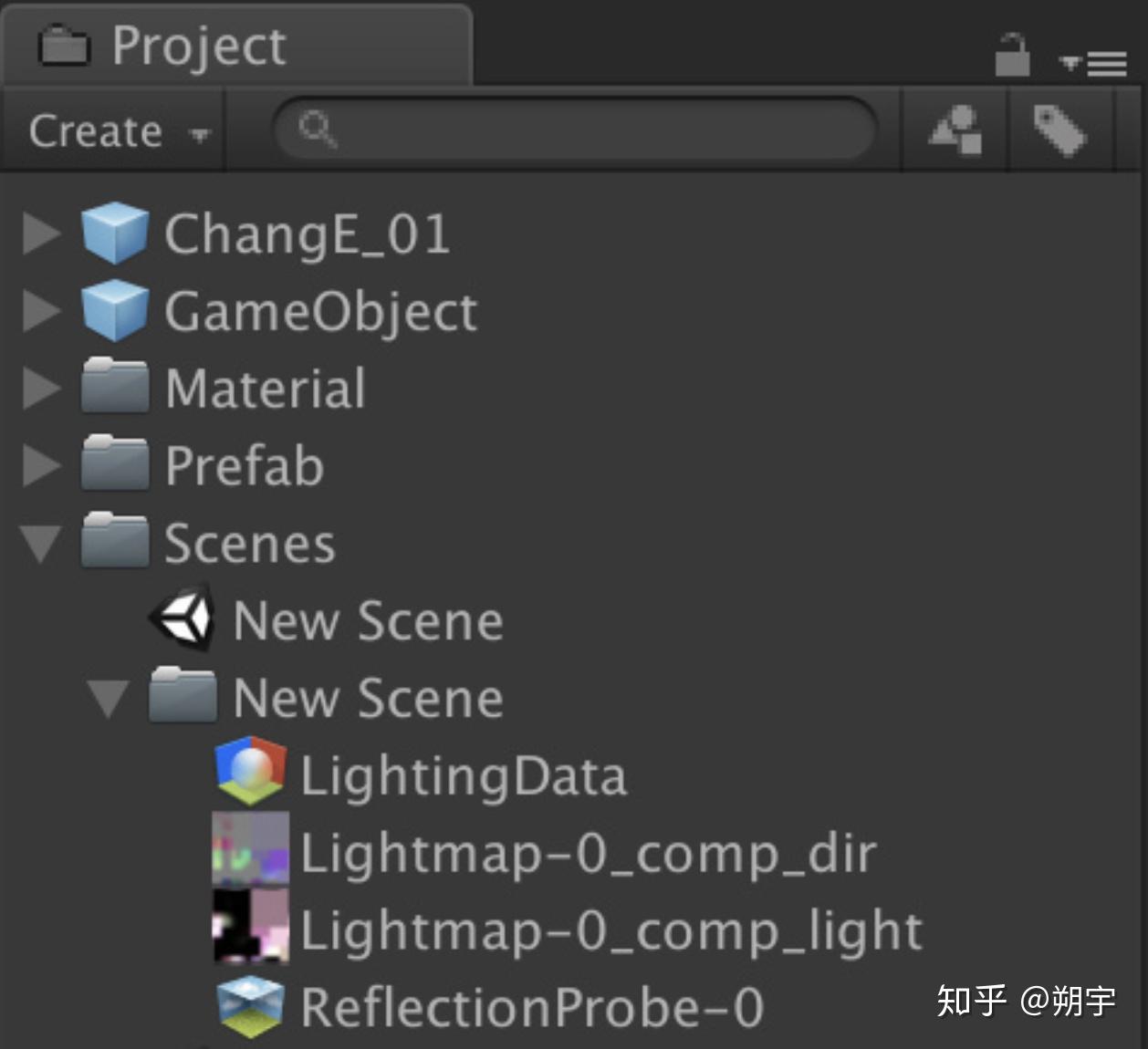
并且可以看到Setpass Calls也从之前的23降到了8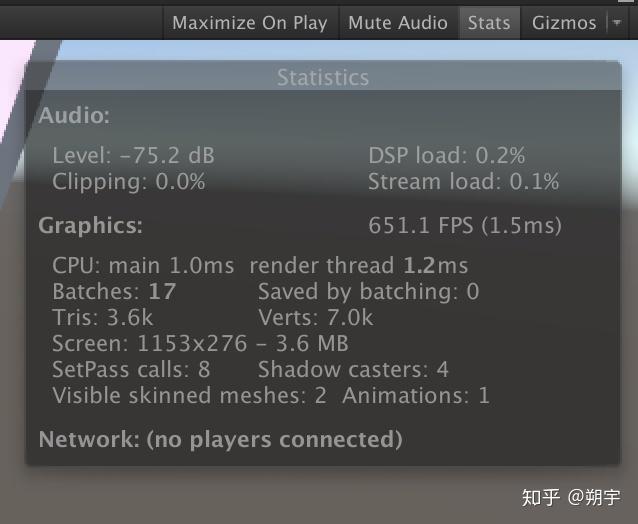
Lightmapping更多的使用方法请参照Unity 官方文档 这里只介绍基本的优化相关
硬阴影和软阴影 (Hard and Soft Shadows):硬阴影和软阴影都将得到渲染。
仅硬阴影 (Hard Shadows Only):仅硬阴影 (hard shadows) 将得到渲染。
禁用阴影 (Disable Shadows):没有阴影会被渲染。
但同时我们注意CPU时间,同一材质的CPU时间明显更高,所以我们要注意增加的CPU时间是否会高于优化节省的时间。
使用静态批处理时,只需要同一个材质且批处理的物体处于静态,同时勾上Static。
可以从下图看到,Setpass Calls同样降低,且CPU时间也没有增加。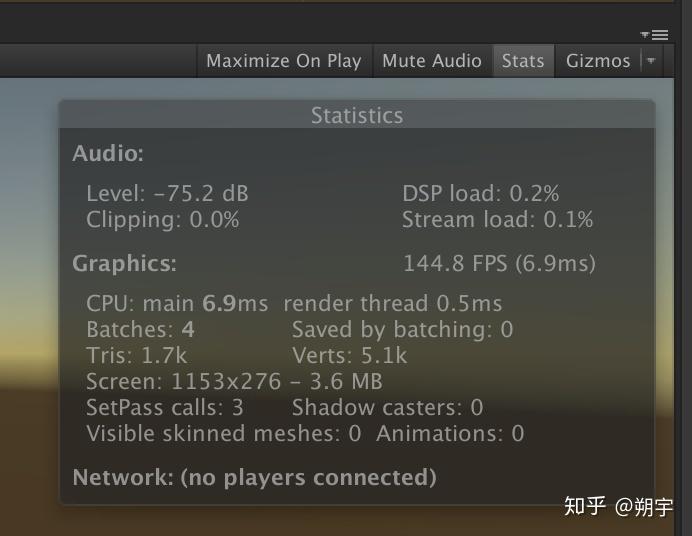
顶点处理的消耗受两方面影响:必须渲染的顶点数量,以及在每个顶点上要进行的操作数量。
GPU渲染优化中,我们常会进行一些shader的优化,这部分内容我希望放到后续shader相关的文章中,以便新手可以有更清晰的概念。
注意这张图片的大小(右下角)
选中Generate Mip maps,点击Apply确定
这里可以发现图片大小发生了变化,这是因为我们使用MipMap技术之后,会对此贴图生成八张精度质量不同的贴图,所以内存占用变大。
很明显,左边没有设置mipmap的物体,即使摄像机拉远,其清晰度也并没有发生变化
其和Mipmap的差异主要在一Mipmap针对贴图,而LOD针对模型。Mipmap可以自动生成八张精度不同的贴图,而LOD必须由我们自己提供三个不同精度的模型。
我们来了解一下LOD的用法,首先需要三个相同的模型,但是这三个模型他们的三角面和顶点数都不同,这样就可以代表三种从高—中—低的层级(这里我使用粒子来代替, 分别用rate 50-20-5)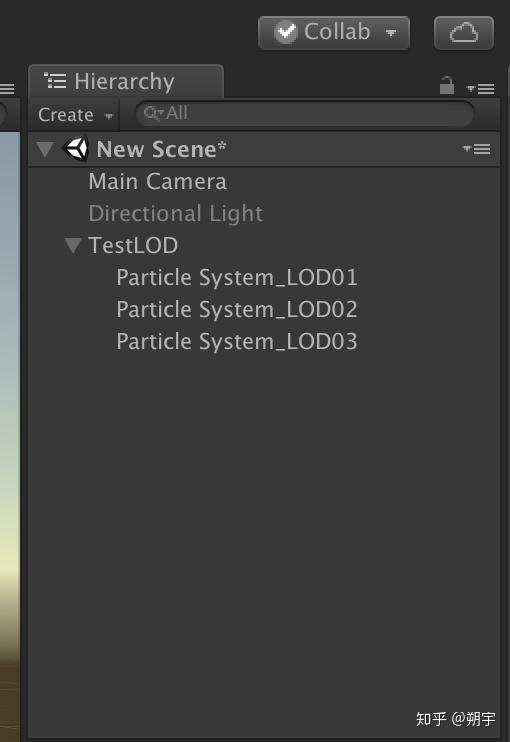
在TestLOD中添加组件LOD Group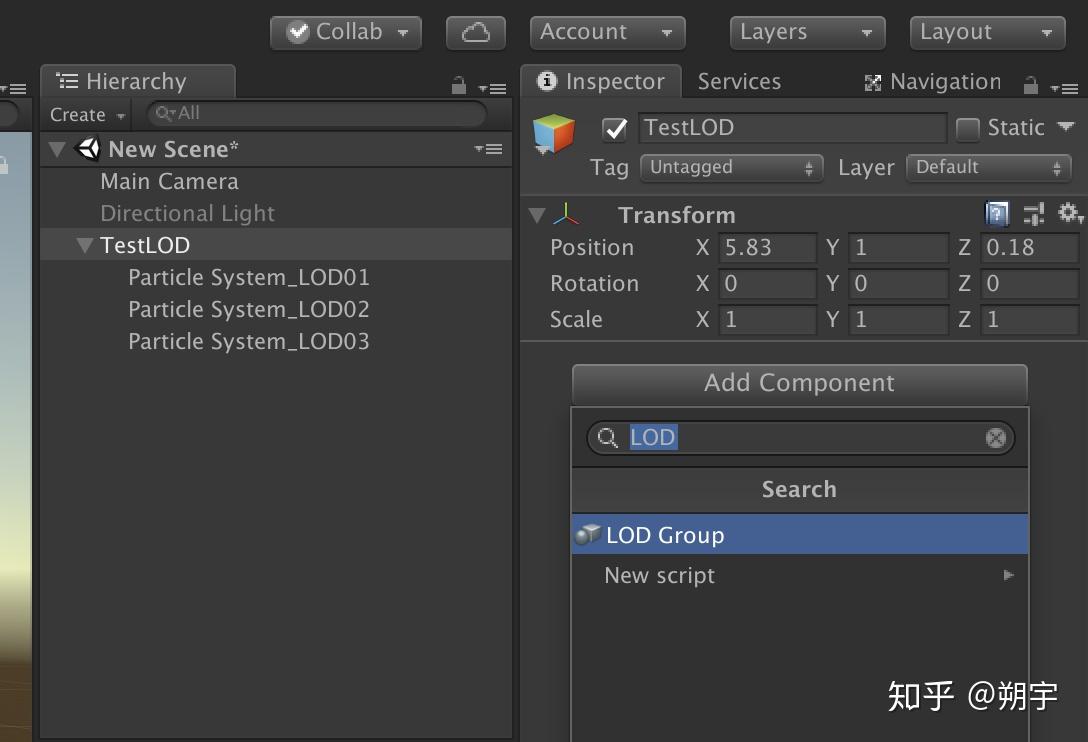
在LOD Group中,我们把对应百分比可见度的物体添加到进去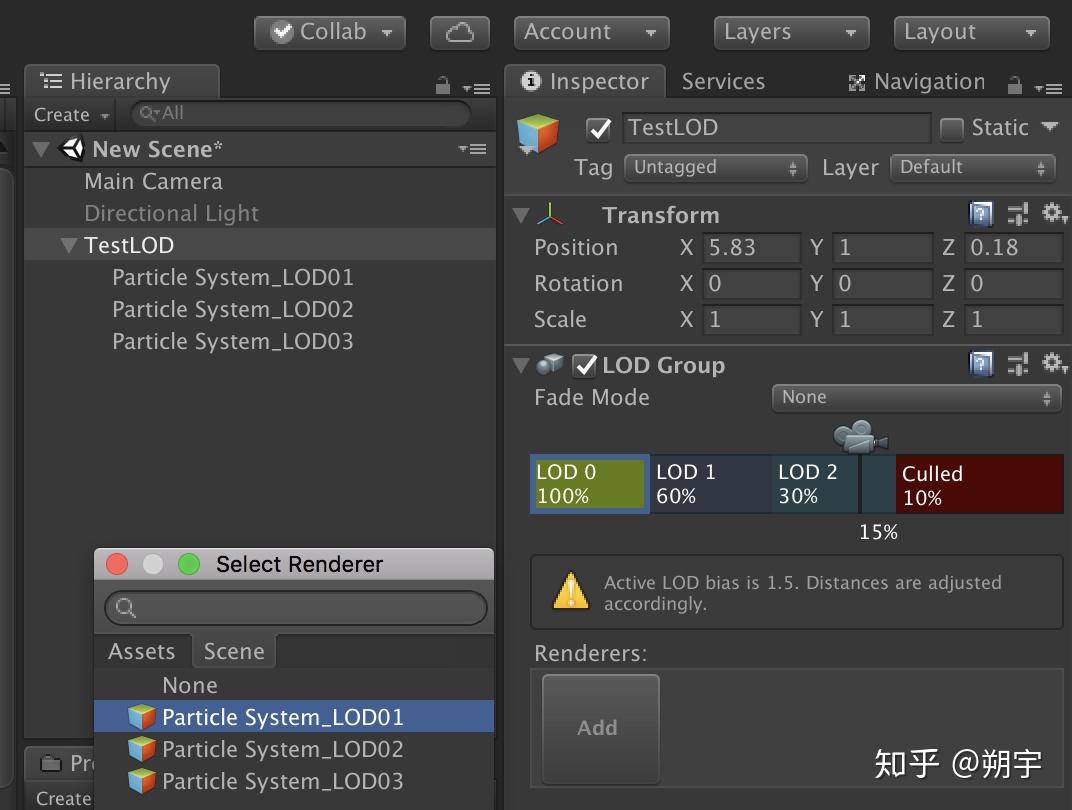
接下来我们看运行时的效果及性能分析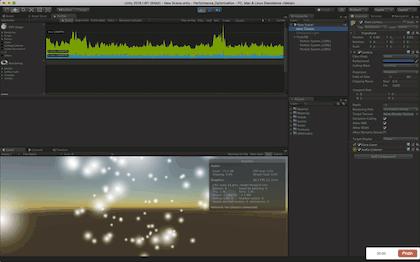

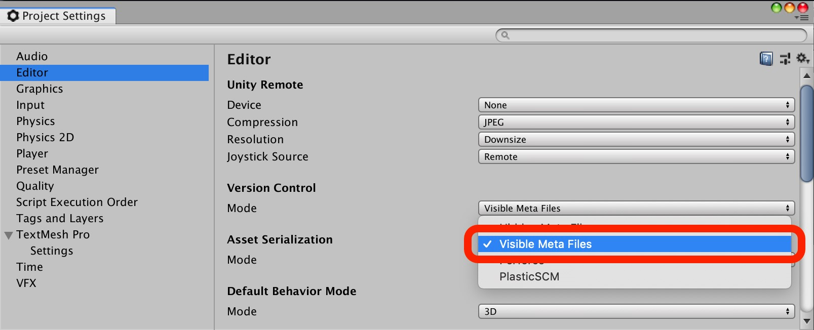
本文翻译自Unity官方发行的电子书《Unity Game Optimization Best Practices》。本文主要介绍了使用Unity作为游戏引擎,从游戏策划到实际研发的最佳实践。其中包括了策划、工作流程、调试、资源管理、代码架构、物理、动画、GPU性能、UI这九大主题。译者水平不足,翻译错漏及不足之处请在下方评论中指出,谢谢 。—— CJT

视频格式是视频播放软件为了能够播放视频文件而赋予视频文件的一种识别符号。
FFMpeg,提供了用于打开视音频的API,开发人员无需关注具体视频格式,直接可以取出视音频流做处理。FFMpeg为例,并不区分视频格式和视频协议;但是GStreamer的话,还时需要指定『视频协议』,但是不区分『视频封装格式』。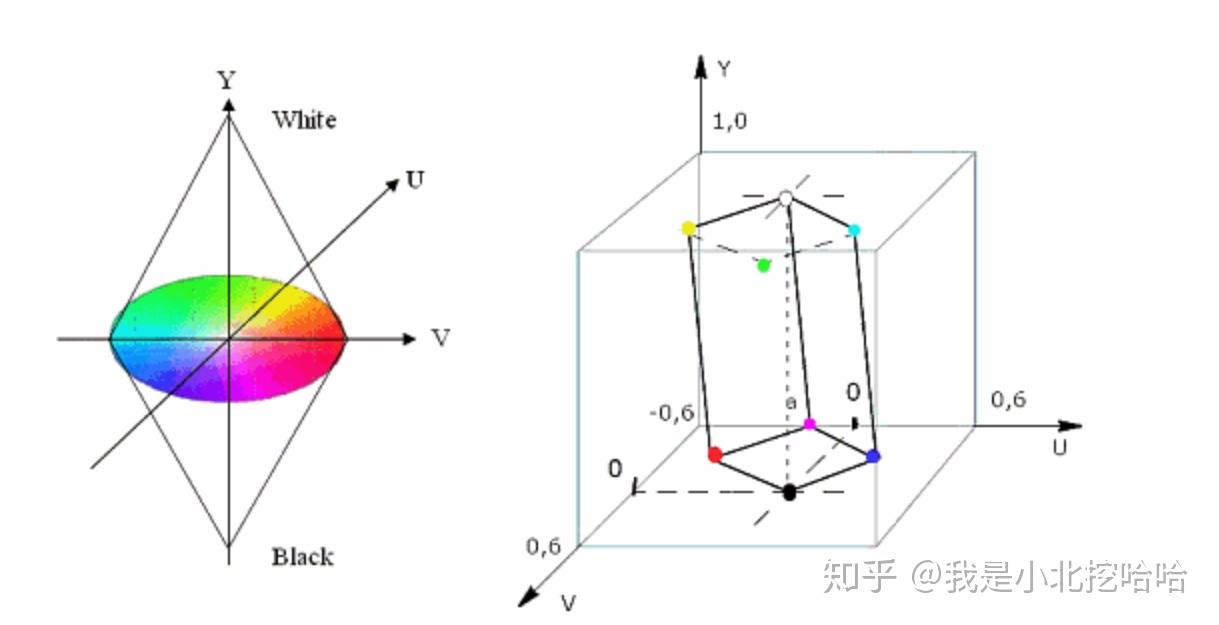
在以前流媒体刚刚兴起时,还没有什么4G/5G,当时为了减小网络传输的带宽的压力,可谓做了种种努力。除了编码/压缩之外,YUV采样率也是一种。
444,422和420是三种『YUV』(在数字电路中指代YCbCr)的采样,三位数分别代表Y\\U\\V(数字电路中为Y\\Cb\\Cr,本段后同)通道的抽样比。所以可以理解,444是全采样;而422是对Y进行全采样,对U\\V分别进行1/2均匀采样。有趣的问题来了,420难道是完全丢弃了V通道/分量数据嘛?答案是否定的。
首先,必须要搞明白一个问题,一帧图像是由一个个像素组成的矩形,譬如4x4的尺寸的图像,就是由16个像素点组成的。在平时接触的『RGB』图像中,每个像素必然至少由R\\G\\B这三个通道组成的(有的图像还有\\alpha分量),每个分量的取值一般都是[0,255],也就是[2^0,2^8],因此经常说一个像素占用3字节(如果还有其他分量,比如RGBA,就另当别论)。『YUV』图像同理,它的每个像素是由Y\\U\\V组成的。
接下来,从整张图像宏观考虑采样问题。还是以4X4的图像为例,444的如下图2-1,这个是形象化成图像的样子,实际在机器内存储并不是这样,具体可以参见博客《图像原始格式一探究竟》。422和420分别如下图2-2和2-3。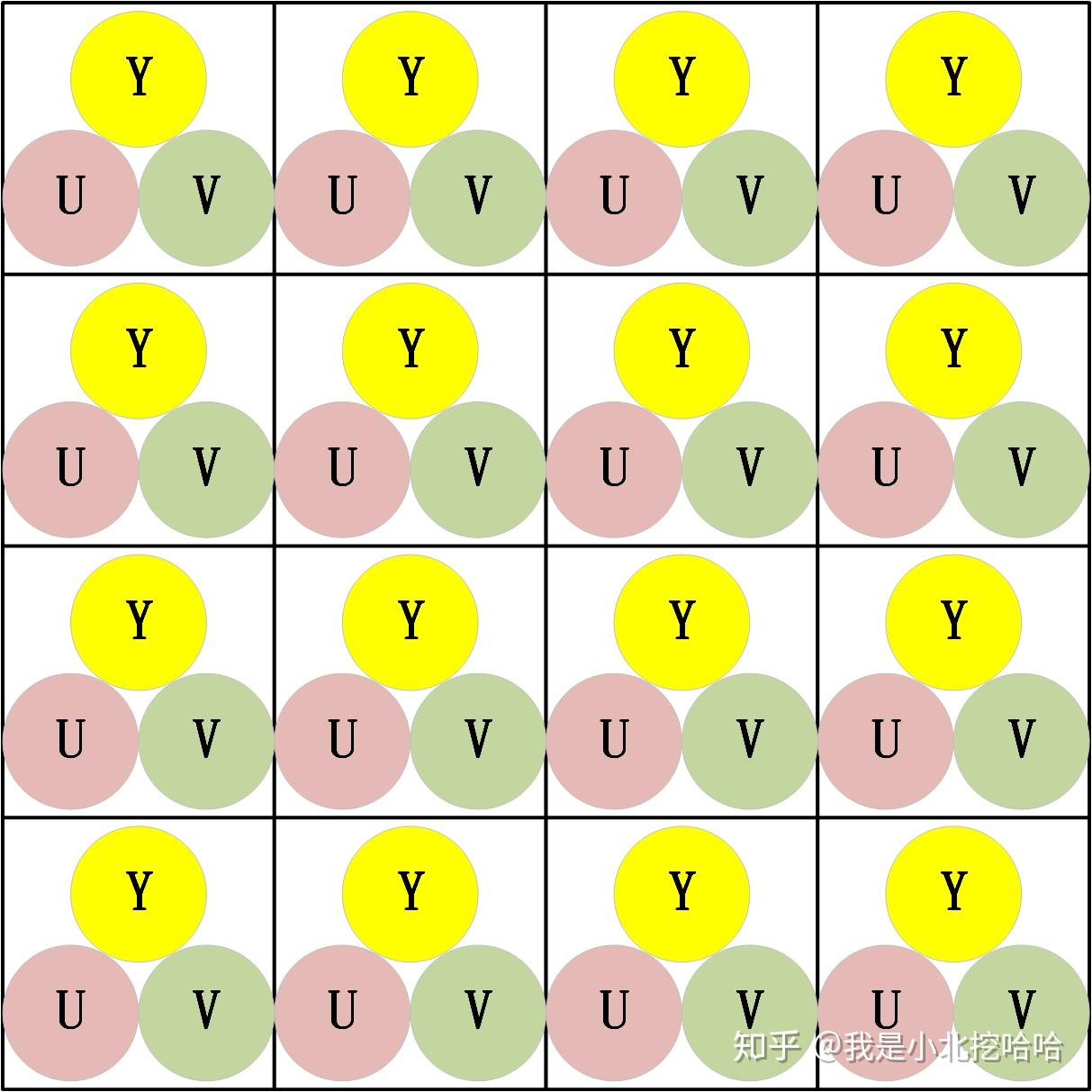
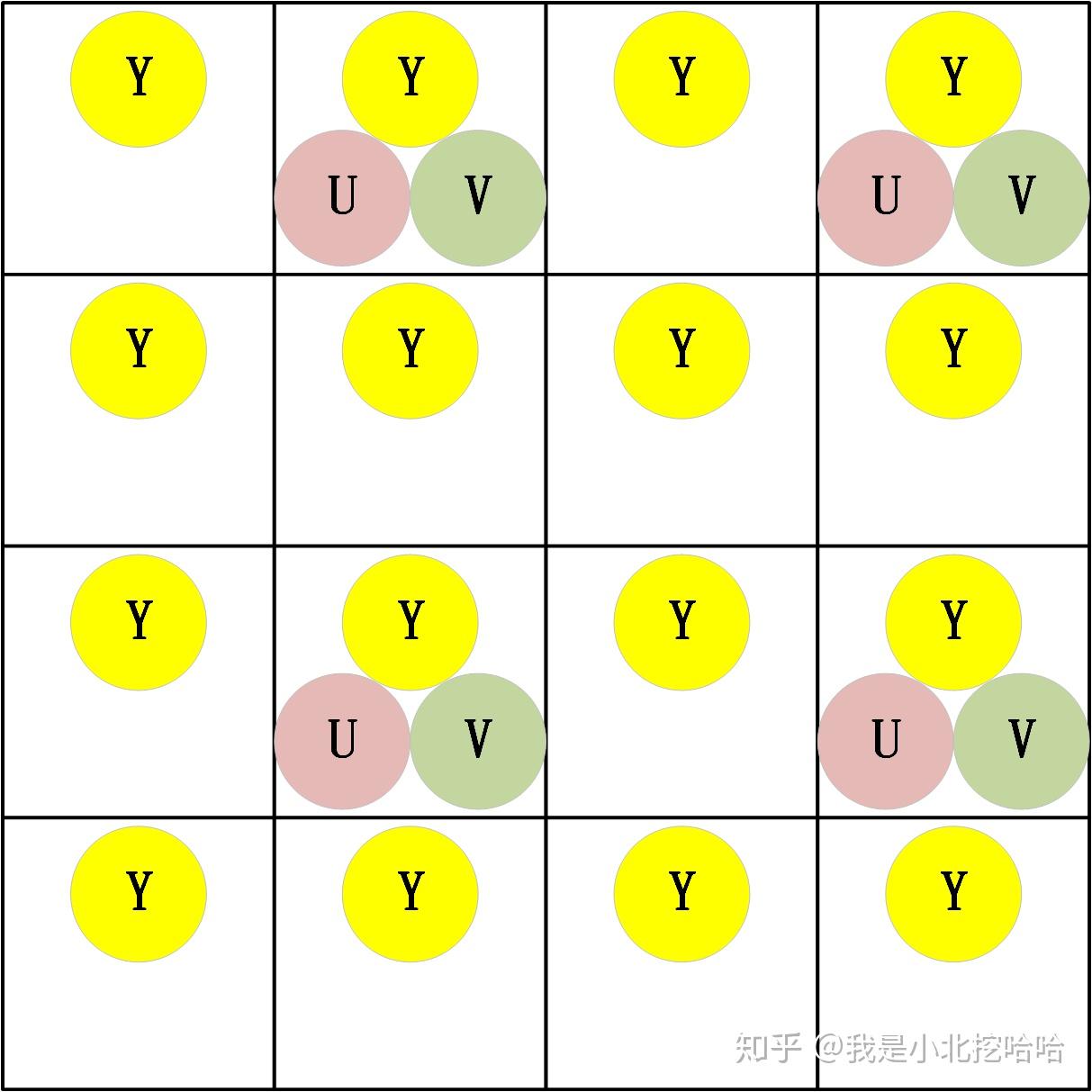
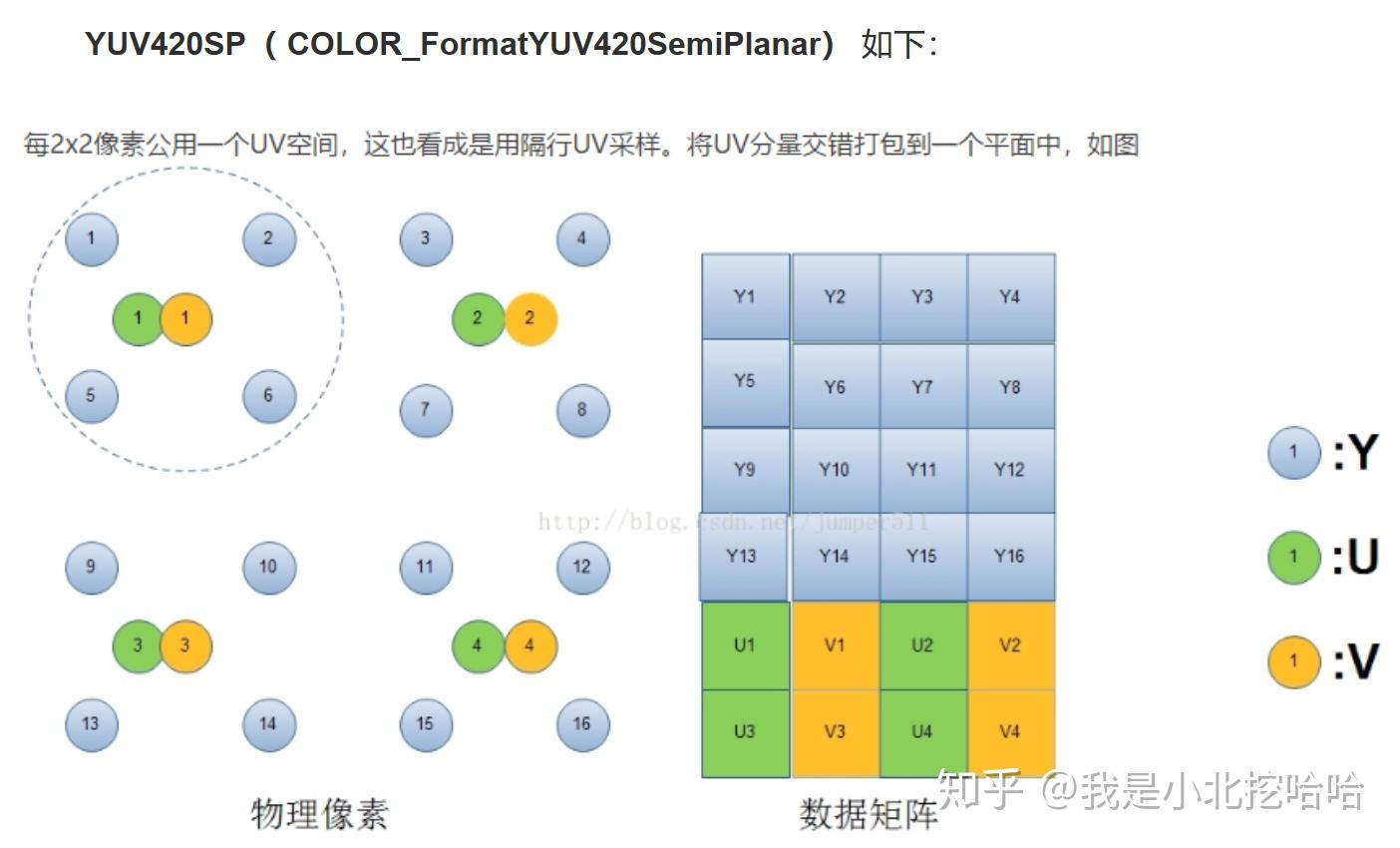
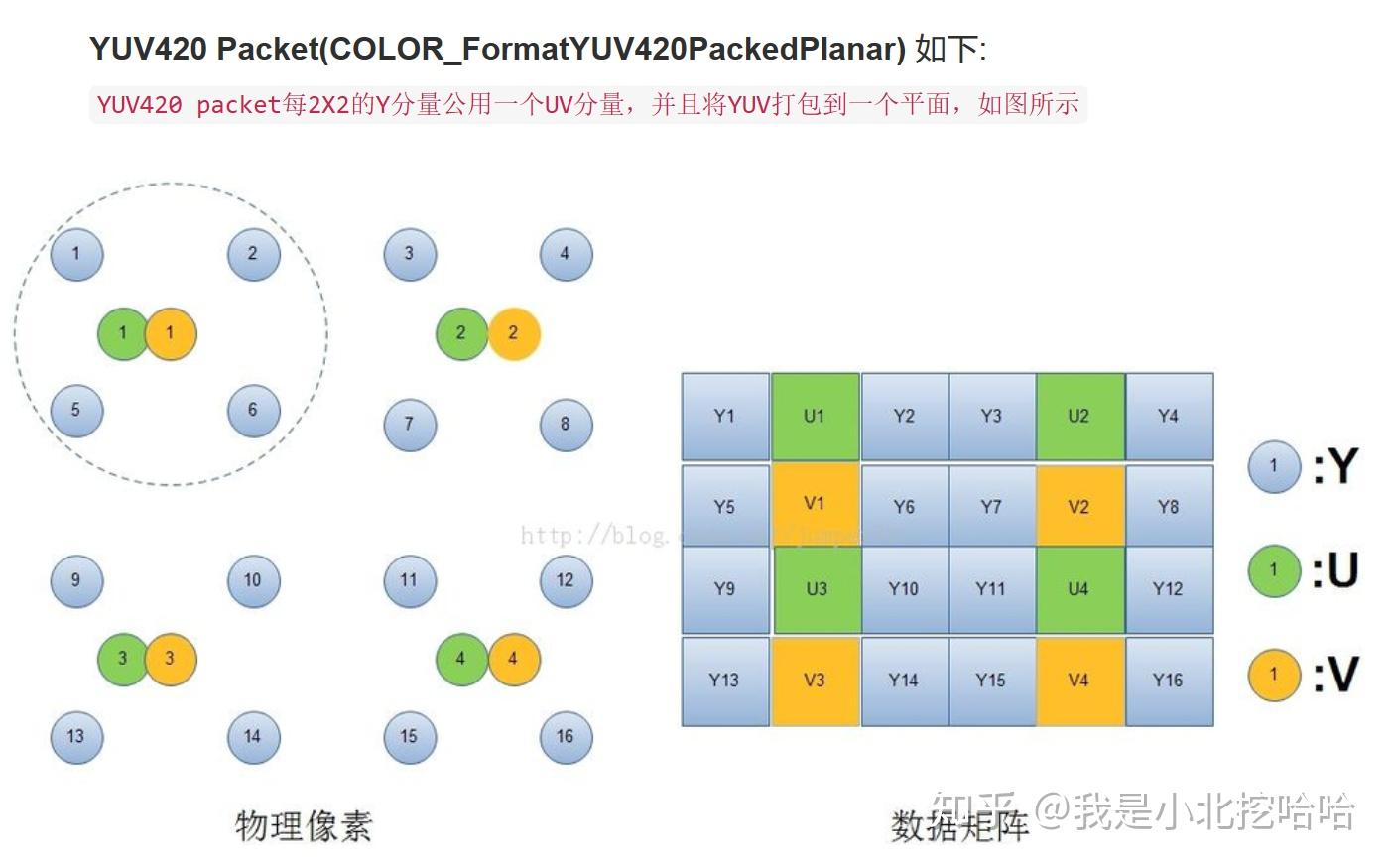
以上统称为『视频的存储格式』,也就是说,计算机是如何存储一帧视频的。
首先,『视频的存储格式』总分为两大类:『打包格式(packed)』和『平面格式(planar)』。前者又被称作『紧凑格式(packed)』。其实除此之外还有『半平面模式(Semi-Planar)』,估计是使用的比较少,因此在很多文章中常被忽略。
笔者很感兴趣,为什么会出现『打包格式』和『平面格式』两大派系,网上搜了很多资料也没找到原因,博客【音视频基础】:I420、YV12、NV12、NV21等常见的YUV420存储格式提到了需要约定存储格式,但也没提到为什么会分成这两种。要么就是派系之争,类似贝叶斯学派和频率学派;要么就是实际应用中逐渐衍生出这两大格式。时至今日,这两个格式还在被使用,因此对于多媒体开发者们都有必要了解。
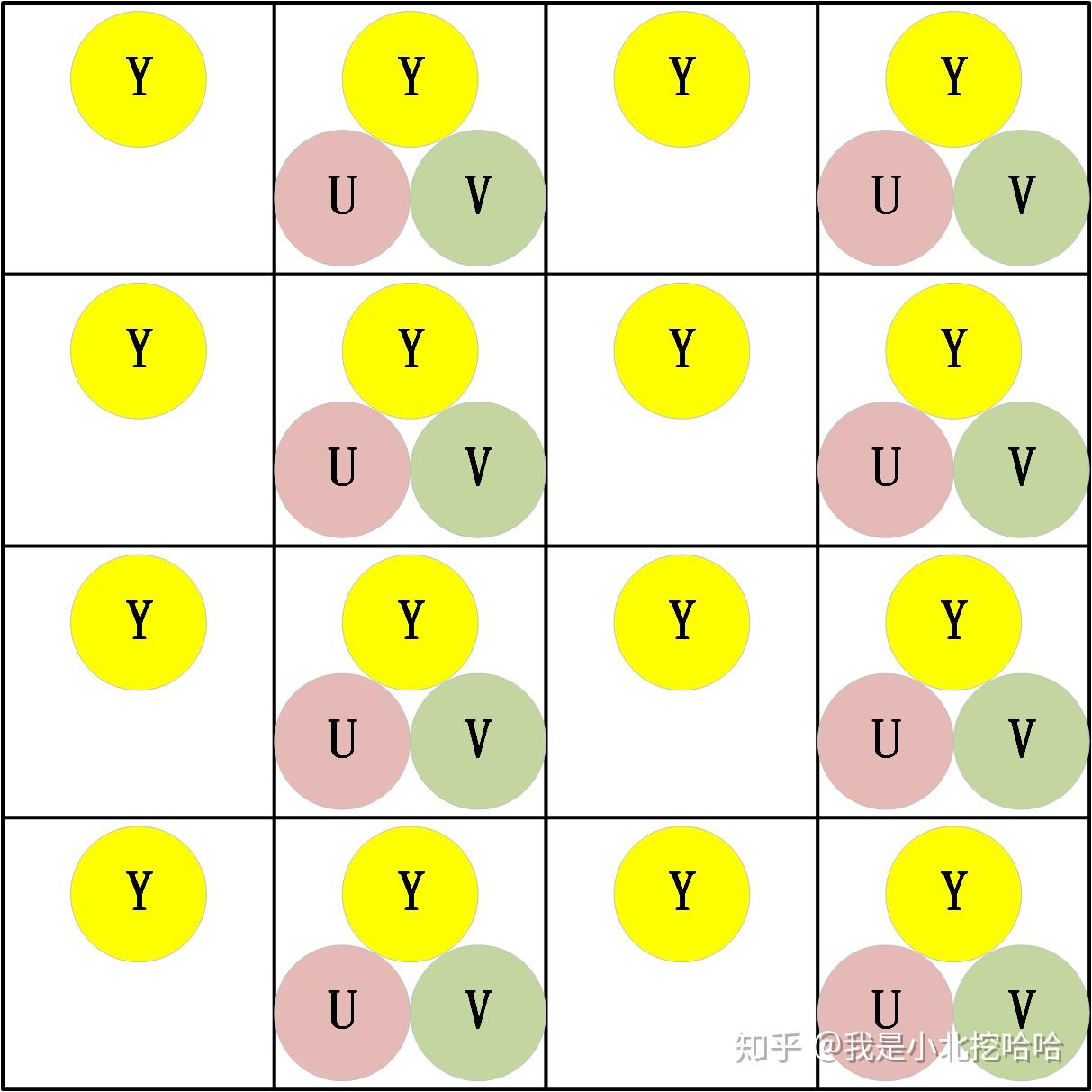
『打包格式』是把Y\\U\\V分量交叉存储,『平面格式』则是把Y\\U\\V严格分开存储,『半平面模式』介于两者之间,Y分量分开存储,U\\V交叉存储。
以下图为例说明『打包格式』、『平面格式』和『半平面模式』应该是非常清楚的,图摘自博客YUV格式初探: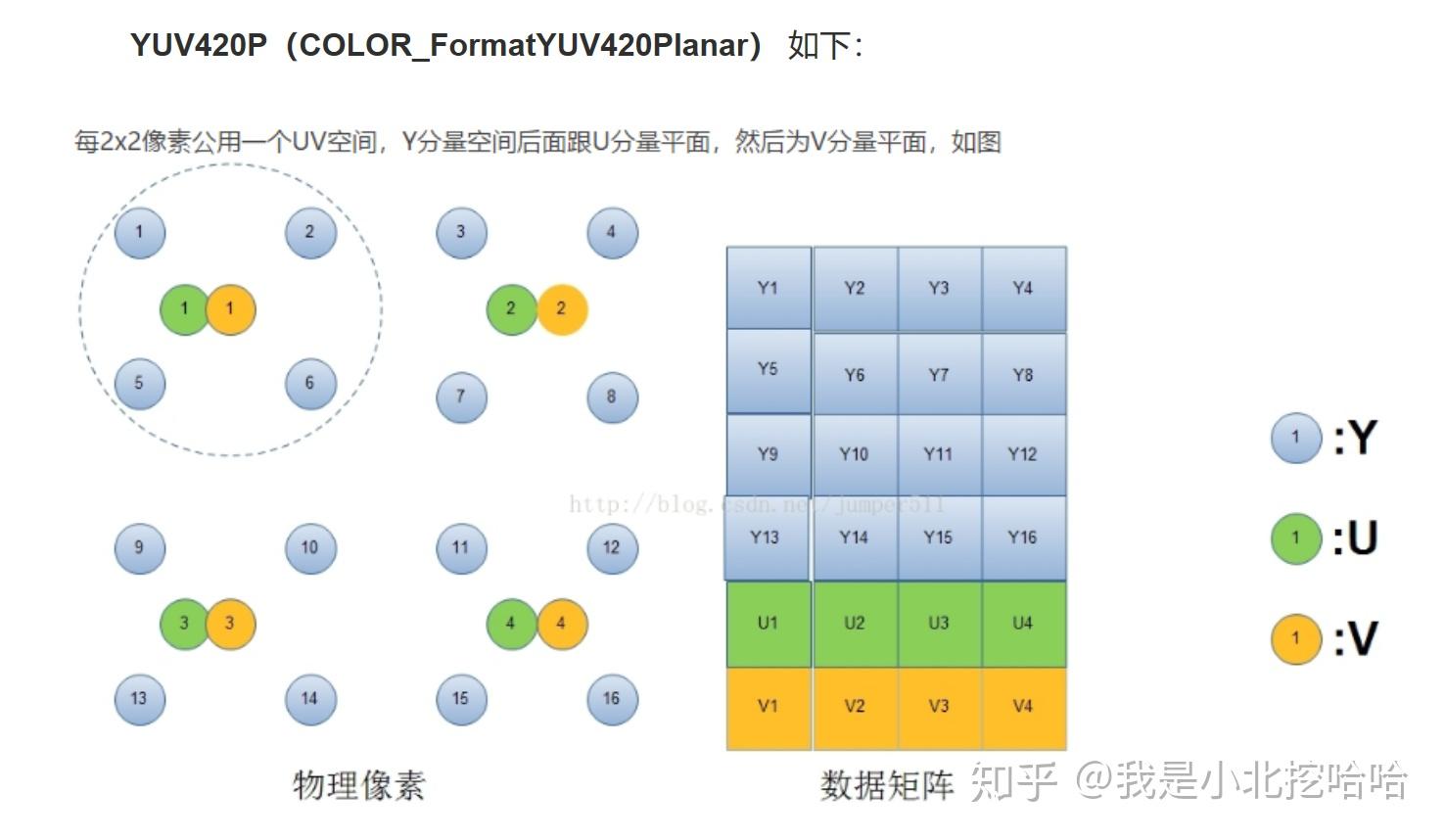
『帧率』,FPS,全称Frames Per Second。指每秒传输的帧数,或者每秒显示的帧数,一般来说,『帧率』影响画面流畅度,且成正比:帧率越大,画面越流畅;帧率越小,画面越有跳动感。一个较权威的说法:
当视频帧率不低于24fps时,人眼才会觉得视频时连贯的,称为“视觉暂留”现象。
因此,才有说法:尽管『帧率』越高越流畅,但在很多实际应用场景中24fps就可以了。
『分辨率』,也常被俗称为『图像的尺寸』或者『图像的大小』。指一帧图像包含的像素的多少,常见有1280x720(720P),1920X1080(1080P)等规格。『分辨率』影响图像大小,且与之成正比:『分辨率』越高,图像越大;反之,图像越小。
『码率』,BPS,全称Bits Per Second。指每秒传送的数据位数,常见单位KBPS(千位每秒)和MBPS(兆位每秒)。笔者认为这个概念真正要理解起来还是需要好好说明的,网上一说:“『码率』与体积成正比:码率越大,体积越大;码率越小,体积越小”;另一说:“『码率』越大,说明单位时间内取样率越大,数据流精度就越高,这样表现出来的的效果就是:视频画面更清晰画质更高”;还有说法是:”『码率』就是『失真度』“。但是笔者有一段时间就是不理解,每秒传输的数据越大,为什么必然就对应画面更清晰?还有体积怎么理解呢?且看下文”三者之间的关系“。
最理想的情况是画面越清晰、越流畅是最好的。但在实际应用中,还需要结合硬件的处理能力、实际带宽条件选择。高『帧率』高『分辨率』,也就意味着高『码率』,也意味着需要高带宽和强大的硬件能力进行编解码和图像处理。所以『帧率』和『分辨率』应该视情况而定。
要说三者之间的关系,其实就是对于『码率』的理解。在码率(BPS)概念中提到了几段摘自网上的说法,说的都太模糊了,笔者直到阅读了文章Video Bitrate Vs. Frame Rate,才真的理解了『码率』。
首先,这些说法都没有交代一个前提:『帧率』、『分辨率』和『压缩率』都会影响『码率』。Video Bitrate Vs. Frame Rate](https://www.techwalla.com/articles/video-bitrate-vs-frame-rate)文章在一开始就明确指出:Bitrate serves as a more general indicator of quality, with higher resolutions, higher frame rates and lower compression all leading to an increased bitrate.
『码率』是更广泛的(视频)质量指标:更高的『分辨率』,更高的『帧率』和更低的『压缩率』,都会导致『码率』增加。进入液晶时代的如今,隔行和逐行其实已经没有太大的意义了,现在的电视或者是显示器都属于固定像素设备,像素点同时发光,并不需要扫描,但是硬要说的话可以认为现在的显示设备都是逐行扫描的,但也并不是说1080P和1080i等就可以淘汰了,毕竟还涉及到摄像机的格式,不过普通观众也不会关心是用什么摄像机拍的,只关心呈现出来的样貌就好了。
但凡接触过一点视频编解码的读者,一定见过I\\P\\B帧,至于IDR可能见的少一些。下面,简单解释每种类型:
英文全称Group Of Pictures,一般来说,指的就是两个I帧之间的间隔,严格来说,是两个IDR帧之间的间隔。笔者对GOP研究的不多,对于网上的说法:“GOP在一定程度上会影响视频画面质量 - 在码率相同的情况下,GOP越大,意味着P\\B帧越多,也就更容易获取较好的图像质量”这个说法存疑。【这里留个坑待填】
笔者是在对视频文件硬做解码的时候,发现实际解码输出的fps是硬解的能力上限,比如一个24fps的视频文件,在用硬件解码时,能够达到100+,当时接到一个需求是:“需要控制视频文件的解码率,让它和文件的fps保持一致”。后来查阅了大量的资料,进而了解了DTS和PTS的概念: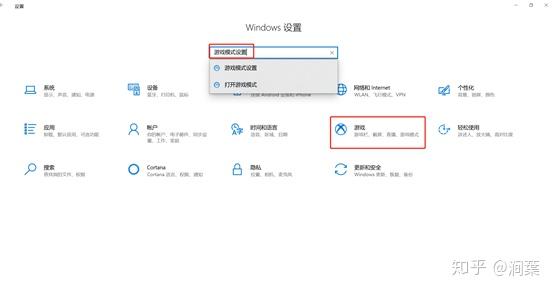






1万=(cpu的核数*1282万)/(1万*60)
cpu的核数=(1万*60*1万)/ 1282万
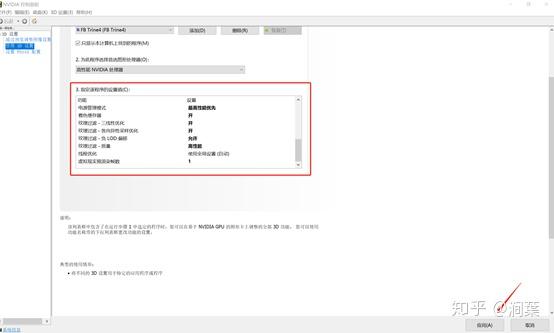
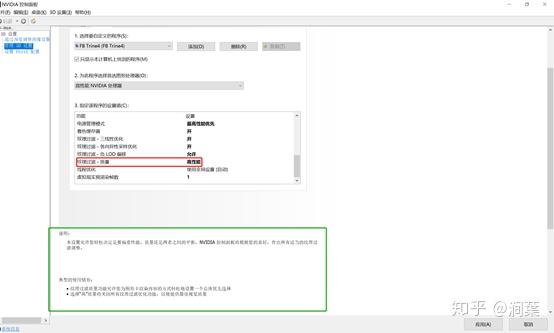
cpu的核数=468核x=(128*1282万)/(x*60)
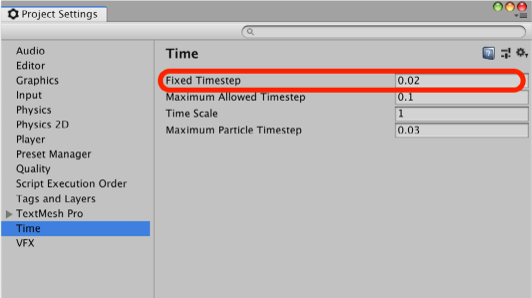
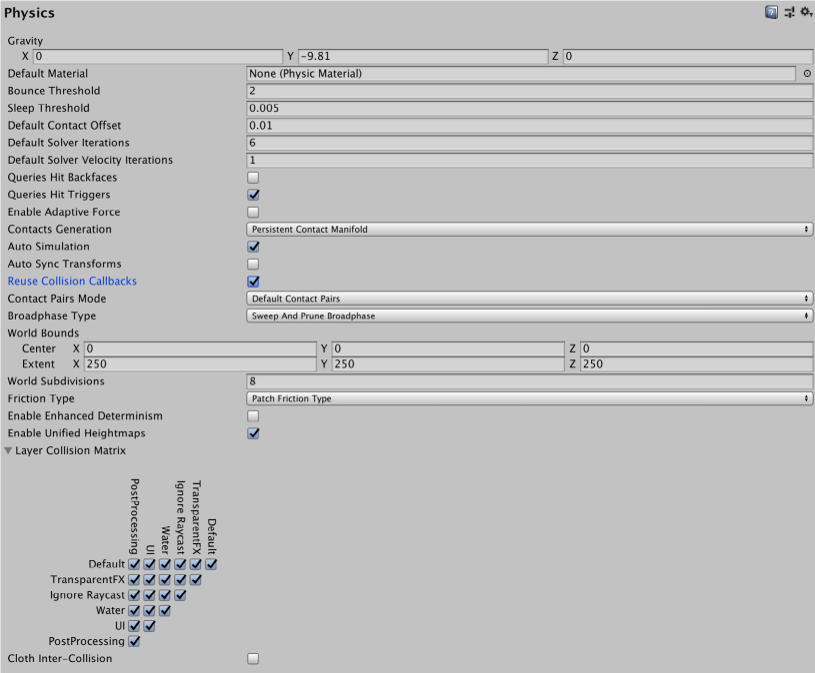
x=5229.65x=(4*12820000)/(x*60)
x=924