发布日期:2024-07-08 来源: 网络 阅读量()
优化思路: 优化思路: 1、hash join 放内存里进行关联。 2、nest loop 从结果1 逐行取出,然后与结果集2进行匹配。 在多表联查时,需要考虑连接顺序问题。 主要有如下几个方面。 EXPLAIN命令可以查看执行计划,这个方法是我们最主要的调试工具。 由于统计信息不是每次操作数据库都进行更新的,一般是在 VACUUM 、 ANALYZE 、 CREATE INDEX等DDL执行的时候会更新统计信息, (5 rows) 一般写法: 如果明确用join的话,执行时候执行计划相对容易控制一些。 我们有的处理中要对同一张表执行很多次insert操作。这个时候我们用copy命令更有效率。因为insert一次,其相关的index都要做一次,比较花费时间。 有时候我们在备份和重新导入数据的时候,如果数据量很大的话,要很几个小时才能完成。这个时候可以先把index删除掉。导入在建index。 如果表的有外键的话,每次操作都没去check外键整合性。因此比较慢。数据导入后在建立外键也是一种选择。 增加这个参数可以提升CREATE INDEX和ALTER TABLE ADD FOREIGN KEY的执行效率。 增加这个参数可以提升大量数据导入时候的速度。 这个参数设置为无效的时候,能够提升以下的操作的速度 表中数据大量变化的时候建议执行VACUUM ANALYZE。 对生产运行的数据库要用定时任务crontb执行如下操作:PostgreSQL 数据库性能调优的注意点,pg数据库性能优化
0、为每个表执行 ANALYZE
1、对于多表查询,查看每张表数据,然后改进连接顺序。
2、先查找那部分是重点语句,比如上面SQL,外面的嵌套层对于优化来说没有意义,可以去掉。
3、查看语句中,where等条件子句,每个字段能过滤的效率。找出可优化处。
比如oc.order_id = oo.order_id是关联条件,需要加索引
oc.op_type = 3 能过滤出1/20的数据,
oo.event_type IN (…) 能过滤出1/10的数据,
这两个是优化的重点,也就是实现确保op_type与event_type已经加了索引,其次确保索引用到了。
0、为每个表执行 ANALYZE
1、对于多表查询,查看每张表数据,然后改进连接顺序。
2、先查找那部分是重点语句,比如上面SQL,外面的嵌套层对于优化来说没有意义,可以去掉。
3、查看语句中,where等条件子句,每个字段能过滤的效率。找出可优化处。
比如oc.order_id = oo.order_id是关联条件,需要加索引
oc.op_type = 3 能过滤出1/20的数据,
oo.event_type IN (…) 能过滤出1/10的数据,
这两个是优化的重点,也就是实现确保op_type与event_type已经加了索引,其次确保索引用到了。
(至于具体什么数据量能在内存中完成排序,不同数据库有不同的配置:
oracle是sort_area_size;
postgresql是work_mem (integer),单位是KB,默认值是4MB。
mysql是sort_buffer_size 注意:该参数对应的分配内存是每连接独占!
)
适用于结果集比较大的情况。
比如都是200000数据
适用于两个结果集,其中一个数据量远大于另外一个时。
结果集一:1000
结果集二:1000000
1、当postgresql中进行查询时,如果多表是通过逗号,而不是join连接,那么连接顺序是多表的笛卡尔积中取最优的。如果有太多输入的表, PostgreSQL规划器将从穷举搜索切换为基因概率搜索,以减少可能性数目(样本空间)。基因搜索花的时间少, 但是并不一定能找到最好的规划。
因此执行计划所用的统计信息很有可能比较旧。 这样执行计划的分析结果可能误差会变大。
以下是表tenk1的相关的一部分统计信息。relname relkind reltuples relpages tenk1 r 10000 358 tenk1_hundred i 10000 30 tenk1_thous_tenthous i 10000 30 tenk1_unique1 i 10000 30 tenk1_unique2 i 10000 30
其中 relkind是类型,r是自身表,i是索引index;reltuples是项目数;relpages是所占硬盘的块数。
例子:
?CREATE TABLE AS SELECT
?CREATE INDEX
?ALTER TABLE SET TABLESPACE
?CLUSTER等。选项 默认值 说明 是否优化 原因 max_connections 100 允许客户端连接的最大数目 否 因为在测试的过程中,100个连接已经足够 fsync on 强制把数据同步更新到磁盘 是 因为系统的IO压力很大,为了更好的测试其他配置的影响,把改参数改为off shared_buffers 24MB 决定有多少内存可以被PostgreSQL用于缓存数据(推荐内存的1/4) 是 在IO压力很大的情况下,提高该值可以减少IO work_mem 1MB 使内部排序和一些复杂的查询都在这个buffer中完成 是 有助提高排序等操作的速度,并且减低IO effective_cache_size 128MB 优化器假设一个查询可以用的最大内存,和shared_buffers无关(推荐内存的1/2) 是 设置稍大,优化器更倾向使用索引扫描而不是顺序扫描 maintenance_work_mem 16MB 这里定义的内存只是被VACUUM等耗费资源较多的命令调用时使用 是 把该值调大,能加快命令的执行 wal_buffer 768kB 日志缓存区的大小 是 可以降低IO,如果遇上比较多的并发短事务,应该和commit_delay一起用 checkpoint_segments 3 设置wal log的最大数量数(一个log的大小为16M) 是 默认的48M的缓存是一个严重的瓶颈,基本上都要设置为10以上 checkpoint_completion_target 0.5 表示checkpoint的完成时间要在两个checkpoint间隔时间的N%内完成 是 能降低平均写入的开销 commit_delay 0 事务提交后,日志写到wal log上到wal_buffer写入到磁盘的时间间隔。需要配合commit_sibling 是 能够一次写入多个事务,减少IO,提高性能 commit_siblings 5 设置触发commit_delay的并发事务数,根据并发事务多少来配置 是 减少IO,提高性能 autovacuum_naptime 1min 下一次vacuum任务的时间 是 提高这个间隔时间,使他不是太频繁 autovacuum_analyze_threshold 50 与autovacuum_analyze_scale_factor配合使用,来决定是否analyze 是 使analyze的频率符合实际 autovacuum_analyze_scale_factor 0.1 当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。 是 使analyze的频率符合实际 
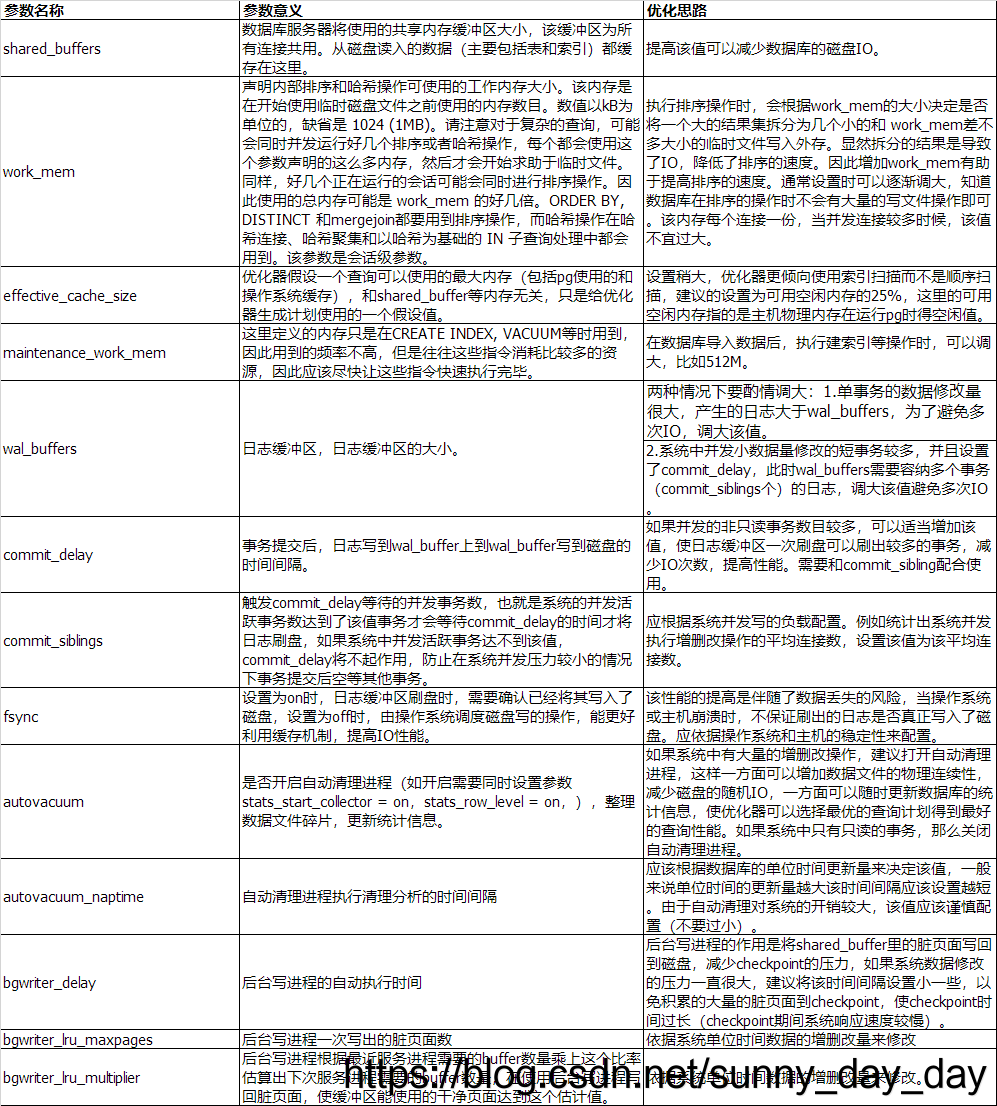
参数名称 参数意义 优化思路 shared_buffers 数据库服务器将使用的共享内存缓冲区大小,该缓冲区为所有连接共用。从磁盘读入的数据(主要包括表和索引)都缓存在这里。 提高该值可以减少数据库的磁盘IO。 work_mem 声明内部排序和哈希操作可使用的工作内存大小。该内存是在开始使用临时磁盘文件之前使用的内存数目。数值以kB为单位的,缺省是 1024 (1MB)。请注意对于复杂的查询,可能会同时并发运行好几个排序或者哈希操作,每个都会使用这个参数声明的这么多内存,然后才会开始求助于临时文件。同样,好几个正在运行的会话可能会同时进行排序操作。因此使用的总内存可能是 work_mem 的好几倍。ORDER BY, DISTINCT 和mergejoin都要用到排序操作,而哈希操作在哈希连接、哈希聚集和以哈希为基础的 IN 子查询处理中都会用到。该参数是会话级参数。 执行排序操作时,会根据work_mem的大小决定是否将一个大的结果集拆分为几个小的和 work_mem差不多大小的临时文件写入外存。显然拆分的结果是导致了IO,降低了排序的速度。因此增加work_mem有助于提高排序的速度。通常设置时可以逐渐调大,知道数据库在排序的操作时不会有大量的写文件操作即可。该内存每个连接一份,当并发连接较多时候,该值不宜过大。 effective_cache_size 优化器假设一个查询可以使用的最大内存(包括pg使用的和操作系统缓存),和shared_buffer等内存无关,只是给优化器生成计划使用的一个假设值。 设置稍大,优化器更倾向使用索引扫描而不是顺序扫描,建议的设置为可用空闲内存的25%,这里的可用空闲内存指的是主机物理内存在运行pg时得空闲值。 maintenance_work_mem 这里定义的内存只是在CREATE INDEX, VACUUM等时用到,因此用到的频率不高,但是往往这些指令消耗比较多的资源,因此应该尽快让这些指令快速执行完毕。 在数据库导入数据后,执行建索引等操作时,可以调大,比如512M。 wal_buffers 日志缓冲区,日志缓冲区的大小。 两种情况下要酌情调大:1.单事务的数据修改量很大,产生的日志大于wal_buffers,为了避免多次IO,调大该值。 2.系统中并发小数据量修改的短事务较多,并且设置了commit_delay,此时wal_buffers需要容纳多个事务(commit_siblings个)的日志,调大该值避免多次IO。 commit_delay 事务提交后,日志写到wal_buffer上到wal_buffer写到磁盘的时间间隔。 如果并发的非只读事务数目较多,可以适当增加该值,使日志缓冲区一次刷盘可以刷出较多的事务,减少IO次数,提高性能。需要和commit_sibling配合使用。 commit_siblings 触发commit_delay等待的并发事务数,也就是系统的并发活跃事务数达到了该值事务才会等待commit_delay的时间才将日志刷盘,如果系统中并发活跃事务达不到该值,commit_delay将不起作用,防止在系统并发压力较小的情况下事务提交后空等其他事务。 应根据系统并发写的负载配置。例如统计出系统并发执行增删改操作的平均连接数,设置该值为该平均连接数。 fsync 设置为on时,日志缓冲区刷盘时,需要确认已经将其写入了磁盘,设置为off时,由操作系统调度磁盘写的操作,能更好利用缓存机制,提高IO性能。 该性能的提高是伴随了数据丢失的风险,当操作系统或主机崩溃时,不保证刷出的日志是否真正写入了磁盘。应依据操作系统和主机的稳定性来配置。 autovacuum 是否开启自动清理进程(如开启需要同时设置参数stats_start_collector = on,stats_row_level = on,),整理数据文件碎片,更新统计信息。 如果系统中有大量的增删改操作,建议打开自动清理进程,这样一方面可以增加数据文件的物理连续性,减少磁盘的随机IO,一方面可以随时更新数据库的统计信息,使优化器可以选择最优的查询计划得到最好的查询性能。如果系统中只有只读的事务,那么关闭自动清理进程。 autovacuum_naptime 自动清理进程执行清理分析的时间间隔 应该根据数据库的单位时间更新量来决定该值,一般来说单位时间的更新量越大该时间间隔应该设置越短。由于自动清理对系统的开销较大,该值应该谨慎配置(不要过小)。 bgwriter_delay 后台写进程的自动执行时间 后台写进程的作用是将shared_buffer里的脏页面写回到磁盘,减少checkpoint的压力,如果系统数据修改的压力一直很大,建议将该时间间隔设置小一些,以免积累的大量的脏页面到checkpoint,使checkpoint时间过长(checkpoint期间系统响应速度较慢)。 bgwriter_lru_maxpages 后台写进程一次写出的脏页面数 依据系统单位时间数据的增删改量来修改 bgwriter_lru_multiplier 后台写进程根据最近服务进程需要的buffer数量乘上这个比率估算出下次服务进程需要的buffer数量,在使用后台写进程写回脏页面,使缓冲区能使用的干净页面达到这个估计值。 依据系统单位时间数据的增删改量来修改。