发布日期:2024-09-09 来源: 网络 阅读量()
优化器的功能:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签。 在pytorch中优化器类名定义为Optimizer,其继承于object父类。优化器中包括如下几个主要基本属性: 还包含如下几个主要的基本方法(函数): 首先我们手动创建一个可学习的参数,给其梯度赋值,然后定义好随机梯度下降优化器准备以其为例: 之后我们依次观察优化器的每个方法都做了些什么。 通过下面代码构造使用实例 输出结果为 以第一个值为例,0.6614变成了0.5614,为什么?因为梯度设置的是1,学习率是0.1,所以一次更新1*0.1就等于0.1,由于更新策略定义了是随机梯度下降,所以要在梯度的反方向上更新,所以就在原权值的基础上减去0.1,由此得到最后结果。这里这么简单是因为我们直接赋值好了梯度,实际情况中梯度是要通过求解得出来的。具体的求解机制可粗浅理解入下,矩阵中每一个元素都影响着下一步的几个特定的输出,那矩阵中某个特定元素的梯度其实就是计算其影响的每个输出对其的偏导之和。 通过下面代码构造使用实例 输出结果为 输出结果中值得注意的是,优化器中的权重地址和实际的权重地址是一样的,所以优化器中的权重和实际权重共享内存。 通过下面代码构造使用实例,给优化器以字典的形式添加一组参数 输出结果为 就可以看见param_group中有两个字典了。 通过代码构造下面使用实例: 输出结果为 可见,初次定义state_dict时,里面的state栏还没有信息。进行了十步更新之后,state_dict中就随时存储信息了。之后用torch.save把训练十步之后的优化器信息存在电脑硬盘上,后面就可以随时加载了。 通过代码构造下面使用实例,构建一个优化器,读取进来pkl,之后调用函数: 输出结果为 可见该函数加载进来了信息,可以接着这个信息进行训练了。 直接通过实例来理解学习率,例如目标函数如下: 然后画出-10到10区间上的均匀分布的500个点的函数图像如下:
该篇笔记整理自余庭嵩的讲解。如果主要看优化器在pytorch中如何使用则可以直接看optim.SGD这一部分的讲解,该部分对优化器pytorch实现时的各变量解释详细,并且其他优化器的变量与其大同小异,在其他部分里就不再重新说明了。本文重点是探讨其中一种优化器的全部数学原理,其他优化器都是基于不同程度上的改进,最后一部分进行了罗列,如果需要详细了解原理可根据所给论文去阅读。
这里的可学习参数一般就是指权值和偏置了,管理指优化器可以修改哪一部分参数。更新就是优化器的更新策略,每个不同的优化器会采取不同的策略去更新参数的值,这里策略通常是梯度下降。
在展开讨论之前,先明确下面几个基本概念:
优化器方法使用实例
optimizer.step()
总结一下,step就是利用已经求好的梯度对权值进行一次更新。optimizer.zero_grad()
optimizer.add_param_group()
optimizer.state_dict()
optimizer.load_state_dict()
学习率
y=4 x 2 y=4x^2 y=4x2
把这里的x看成是权重,y看成是loss,下面通过代码来理解学习率的作用。
首先构造这个函数:
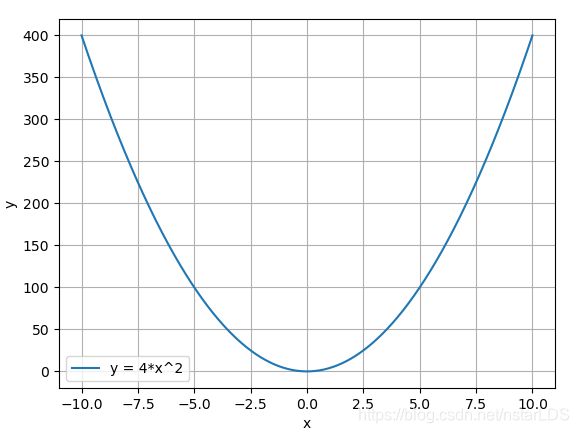
接下来模拟一下优化的过程,假如不考虑学习率的概念,直接令其为1即可,迭代四次。